NAVIGA TRA LE SOTTOSEZIONI
VERIFICA E VALIDAZIONE
Questa attività chiude tecnicamente le fasi di analisi ed attività. Il suo scopo è quello di rilevare difetti iniettati nelle rispettive fasi così che il loro superamento costi il meno possibile.
La sperimentazione di quest’attività è stata condotta a chiusura dell’analisi, ovvero sulla V&V del BRD.
Q3.1 - QUANTI SONO I RILIEVI EFFETTUATI SUI BRD DI PROGETTO?
Il Numero di rilievi (NR) associato ad ogni progetto è normalizzato sul costo dell’intero progetto (Tprog). Nella ipotesi che il costo del progetto sia un indicatore significativo della complessità dello stesso.
Numero di Rilievi Normalizzato =NRN = NR/Tprog*100
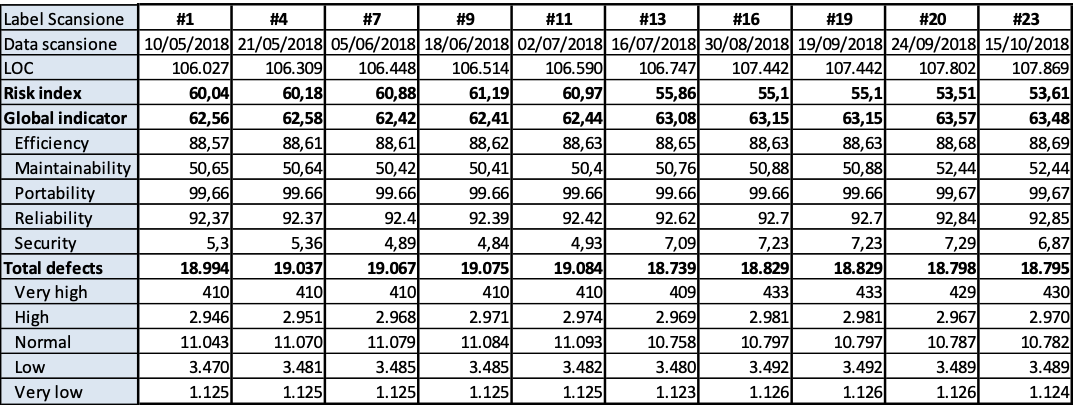
I casi di studio eseguiti sono 41 su diversi clienti che sono stati eseguiti su progetti di diversa complessità (Tprog) che hanno, quindi richiesto differenti impegni-persona per la produzione del BRD. I TAM osservati sono 10. Per privacy e per assicurare che la rilevazione dei dati abbia solo lo scopo di indagine, essi sono identificati con un codice. In figura 3.1 sono mostrati i dati rilevati.
 (Figura 3.1. Intensità dei rilievi nei BRD)
(Figura 3.1. Intensità dei rilievi nei BRD)
I rilievi nella V&V del BRD consentono di eliminare difetti iniettati nel software già nell’analisi evitando così sprechi dovuti alla maggiorazione dei costi che comporterebbero le modifiche richieste dagli stessi difetti se rilevati durante lo UAT. Infatti, i rilievi nella V&V dell’analisi aumenta la probabilità di correttezza e completezza del BRD che è la base di partenza per la progettazione del TS. Un buon progetto di TS diminuisce la probabilità di rilevare failure durante lo UAT che, come è stato detto, hanno un costo di riparazione molto alto.
 (Figura 3.1-g. Intensità dei rilievi)
(Figura 3.1-g. Intensità dei rilievi)
In figura 3.1-g sono mostrati la box plot della distribuzione dei rilievi in tutti i progetti oggetto di indagine. Si rileva che esclusi gli outlier, il numero di rilievi si mantiene entro i 20 rilievi, ma esiste una dispersione rilevante che evidenzia la necessità di miglioramento dello standard di produzione del BRD, ovvero nella fase di analisi. La box plot della distribuzione degli NRN mostra una soddisfacente dispersione ma molti outlier, quindi suggerisce sempre un miglioramento dello standard BRD.
Q3.2 - COME SI DISTRIBUISCONO I RILIEVI PER TIPO E TASSONOMIA?
Nei 41 casi di studio considerati nelle precedenti osservazioni sono stati rilevati il Tipo e la Tassonomia dei rilievi nelle rispettive V&V, secondo le classi standard definite in Auriga e riportate nell’intestazione delle colonne delle rispettive tavole (Figura 3.2.a e Figura 3.2.b).
I TAM osservati sono sempre gli stessi 10. Per privacy e per assicurare che la rilevazione dei dati abbia solo lo scopo di sperimentazione, sono anonimi. Anche in questi casi di studio i TAM sono classificati nelle stesse due classi di anzianità dette prima.
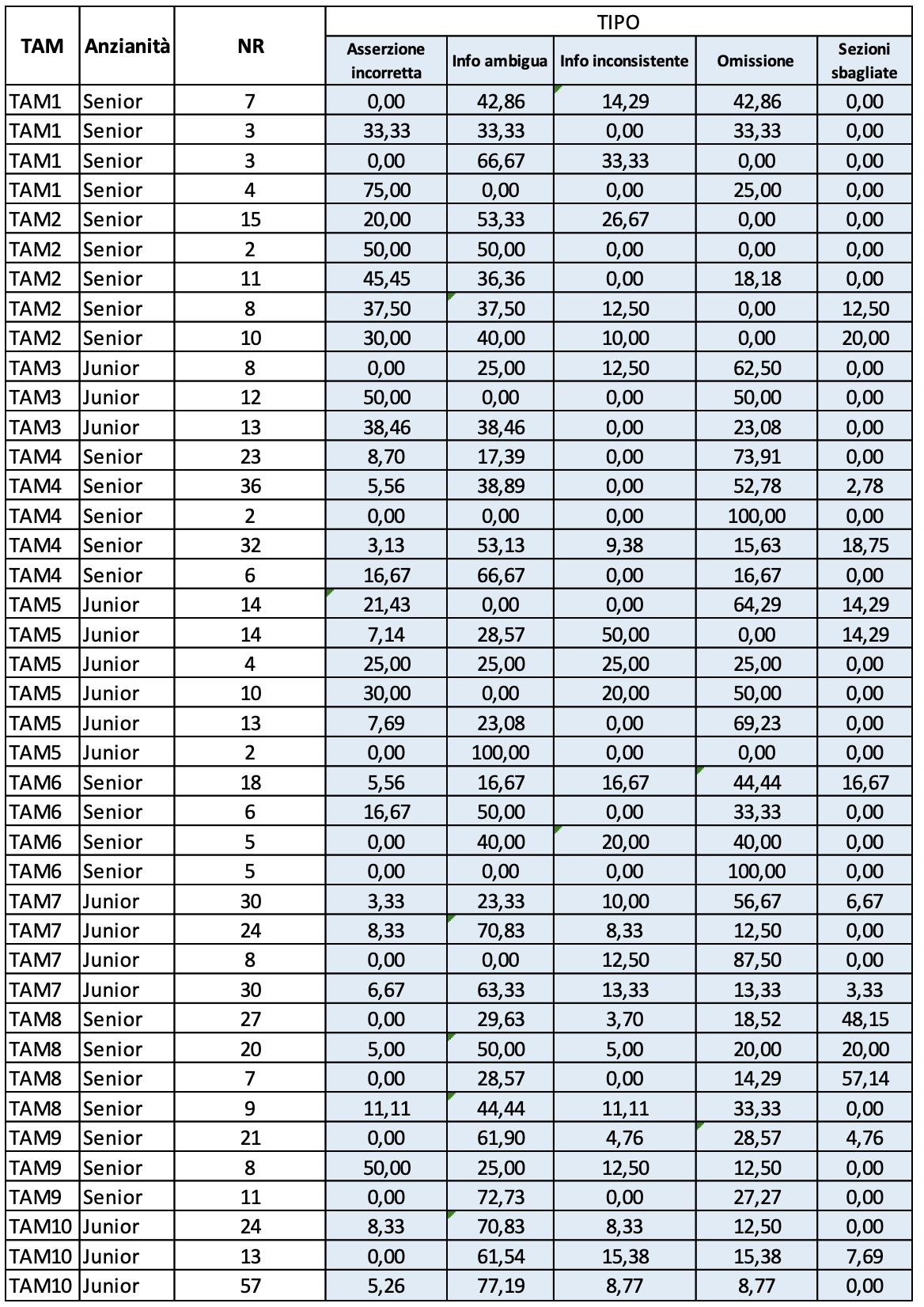 (Figura 3,2.a Distribuzione dei rilievi per Tipo)
(Figura 3,2.a Distribuzione dei rilievi per Tipo)
In figura 3.2.a-g è riportata la box plot della distribuzione dei rilievi tra i diversi tipi definiti dallo standard del BRD. Si rileva che i più numerosi e con maggiore dispersione sono gli “Info ambigua” e gli “omissione”. I primi indicano che il miglioramento del processo di analisi deve curare l’abilità nell’uso dello standard. Entrambi suggeriscono che deve essere curata anche l’approfondimento della conoscenza del dominio applicativo.
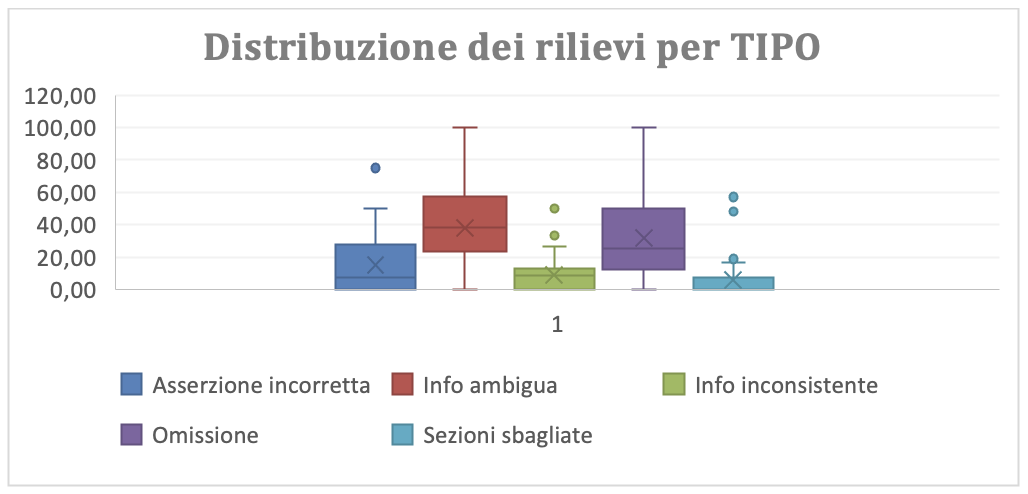 (Figura 3.2.a-g Distribuzione grafica dei rilievi per Tipo)
(Figura 3.2.a-g Distribuzione grafica dei rilievi per Tipo)
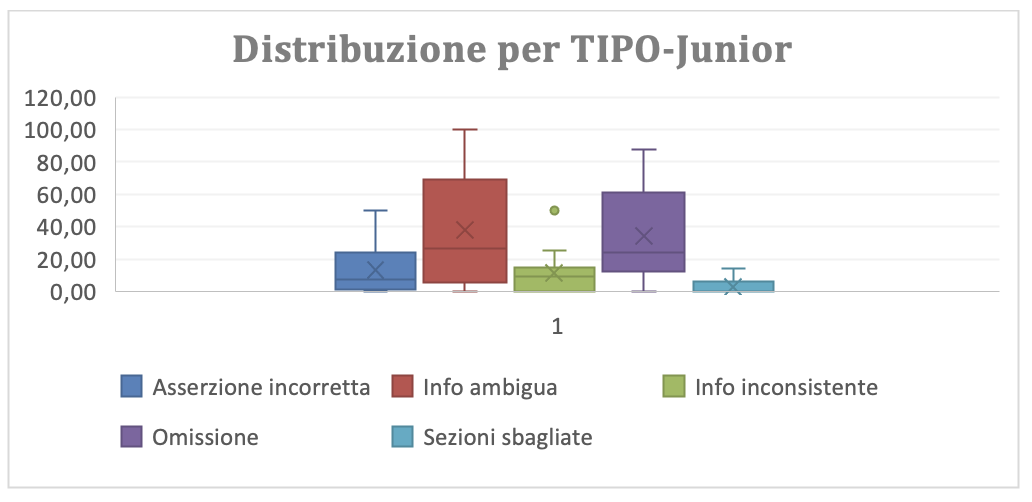 (Figura 3.2.a-g-junior Distribuzione grafica dei rilievi per Tipo per gli Junior)
(Figura 3.2.a-g-junior Distribuzione grafica dei rilievi per Tipo per gli Junior)
Le figure che mostrano la distribuzione dei rilievi per tipo dettagliata per i Tam Junior (Figura 3.2.a-g-junior) e senior (Figura 3.2.a-g-senior) confermano la necessità di approfondire la conoscenza del dominio applicativo. Infatti gli Junior hanno entrambi i tipi di rilievi (“info ambigua” e “Omissione”) messi in evidenza con maggiore rilevanza e dispersione dei senior.
L’analisi dei dati in figura 3.2.b è più agevole se fatta attraverso la sua rappresentazione grafica per box-plot (figura 3.2.b-g). Questa evidenzia molti outlier e l’incombenza dei rilievi per “documentazione”, “funzione” e dei “dati”. La presenta di molti outlier suggerisce che lo standard BRD è conosciuto in modo diversificato tra i soggetti sperimentali, ovvero è necessario rafforzare la conoscenza e l’abilità all’uso dello standard BRD.
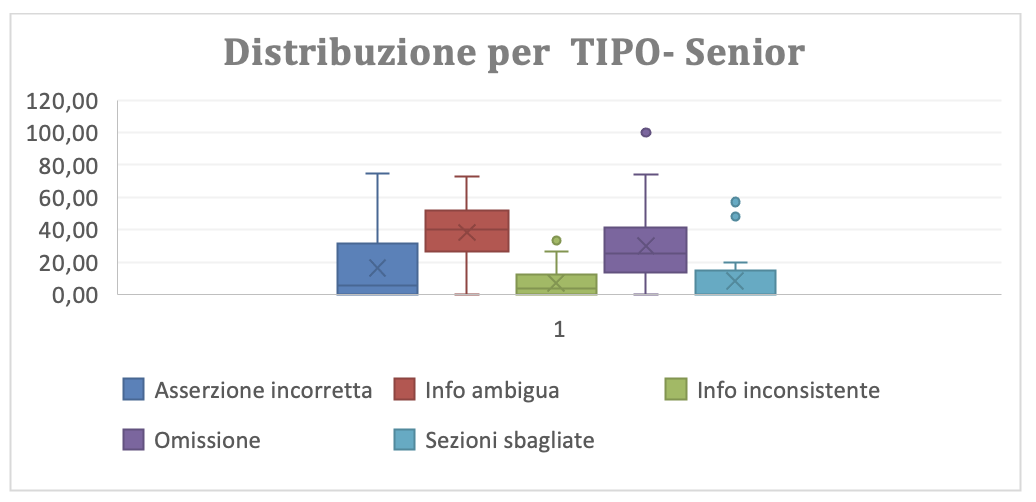 (Figura 3.2.a-g-senior Distribuzione grafica dei rilievi per Tipo per i senior)
(Figura 3.2.a-g-senior Distribuzione grafica dei rilievi per Tipo per i senior)
La distribuzione non cambia rilevantemente se la si dettaglia per junior e senior. Anzi sembrerebbe che i senior producano BRD di qualità inferiore in quanto a “documentazione”, a “funzione” e a Dati”. Assunto che i senior conoscano il dominio applicativo meglio che gli Junior, l’unica spiegazione ragionevole è che lo standard BRD, in termini di contenuti e di processo di produzione debba essere approfondito in Auriga.
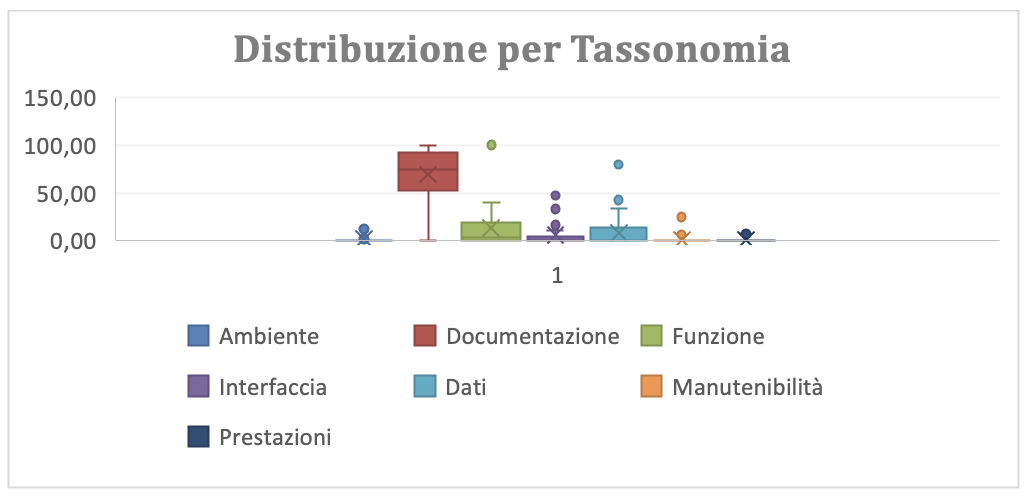 (Figura 3.2.b-g Distribuzione grafica dei rilievi per Tassonomia)
(Figura 3.2.b-g Distribuzione grafica dei rilievi per Tassonomia)
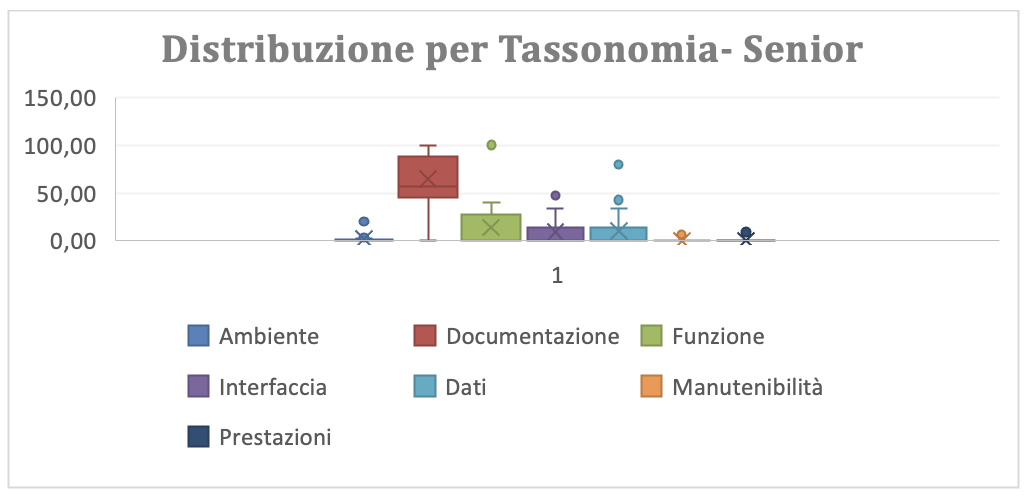 (Figura 3.2.b-g-senior Distribuzione grafica dei rilievi per Tipo per i Senior)
(Figura 3.2.b-g-senior Distribuzione grafica dei rilievi per Tipo per i Senior)
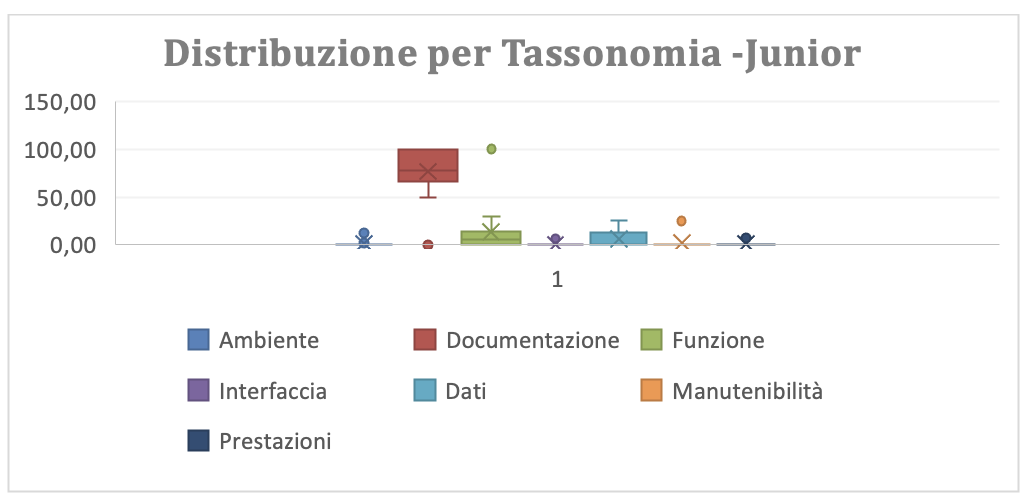 (Figura 3.2.b-g-junior Distribuzione grafica dei rilievi per Tipo per gli Junior)
(Figura 3.2.b-g-junior Distribuzione grafica dei rilievi per Tipo per gli Junior)
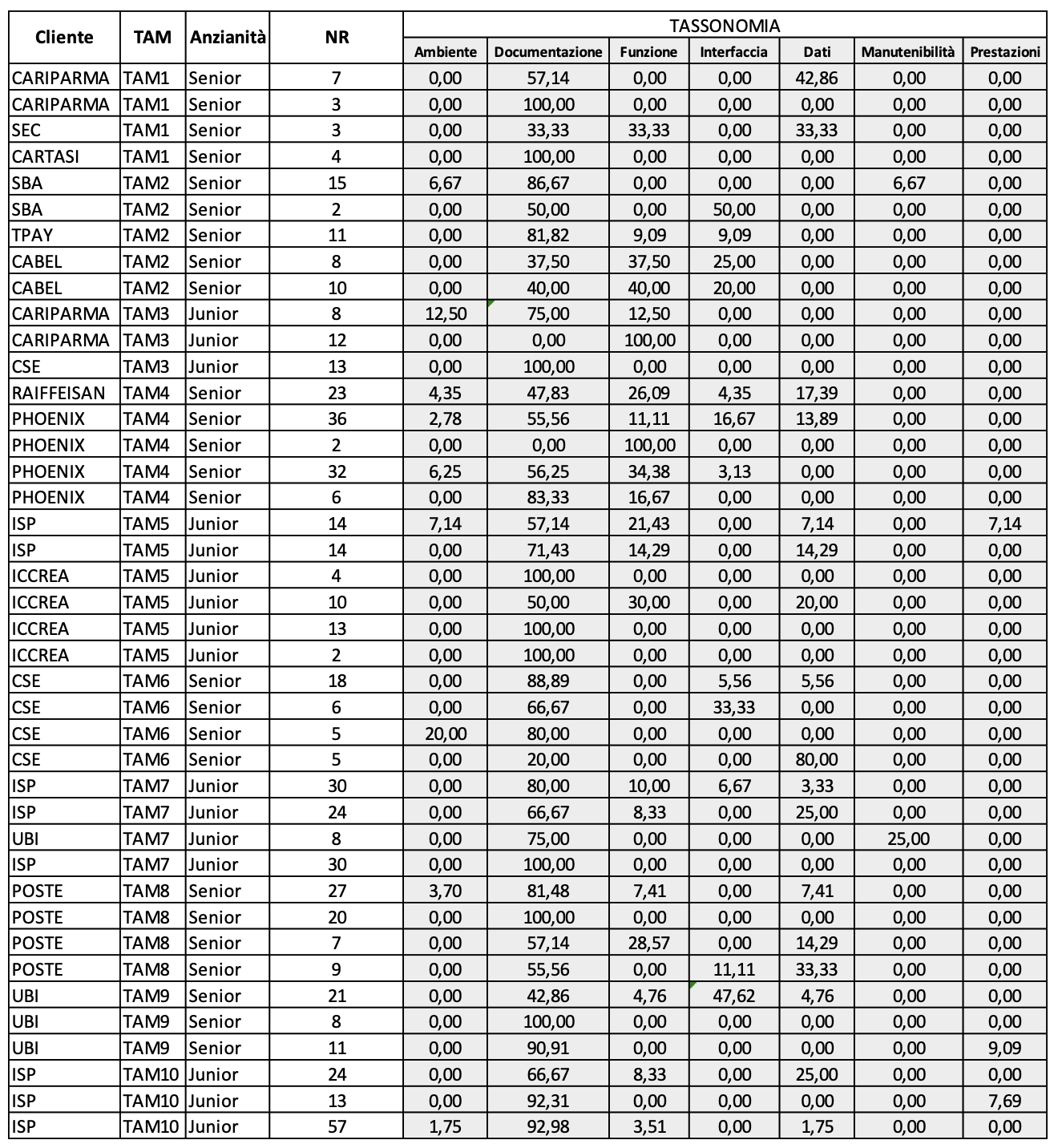 (Figura 3.2.b. Distribuzione dei rilievi per Tassonomia)
(Figura 3.2.b. Distribuzione dei rilievi per Tassonomia)
Q3.4 - Quanti casi di test falliscono nel test di sistema?
Una buona V&V deve aumentare la qualità del prodotto della fase tecnica che ha chiuso. Questo deve avere come conseguenza principale la scoperta dei difetti iniettati nella fase tecnica di riferimento e quindi fermare l’impatto di propagazione di tali difetti nelle fasi tecniche successive. In ultima analisi i piani di test progettati sulla base della documentazione prodotta nella fase tecnica di riferimento devono avere minori casi falliti, grazie alla migliore qualità indotta nel software prodotto a partire da tale documentazione.
In questo PIA, questa asserzione è stata sperimentata sull’analisi, quindi il documento preso in considerazione è il BRD, il corrispondente piano di test è il Test di Sistema (TS).
Ciò premesso le misure rilevate sono state
NCT = numero di casi test totali nel test di sistema.
NCFS= numero di casi di test di sistema falliti in un piano di test di sistema.
NCFSN = numero di casi di test di sistema falliti in un piano di test di sistema, normalizzati =NCFS/NCT*100. La normalizzazione consente di confrontare piani di test di diversa complessità e dimensione.
Sono stati considerati 11 casi di studio prima della introduzione della V&V ed 11 casi di studio dopo l’introduzione della V&V.
In Figura 3.3 sono riportati i risultati dei casi di studio eseguiti: i primi 11 sono quelli senza, i secondi casi di studio sono con la V&V.
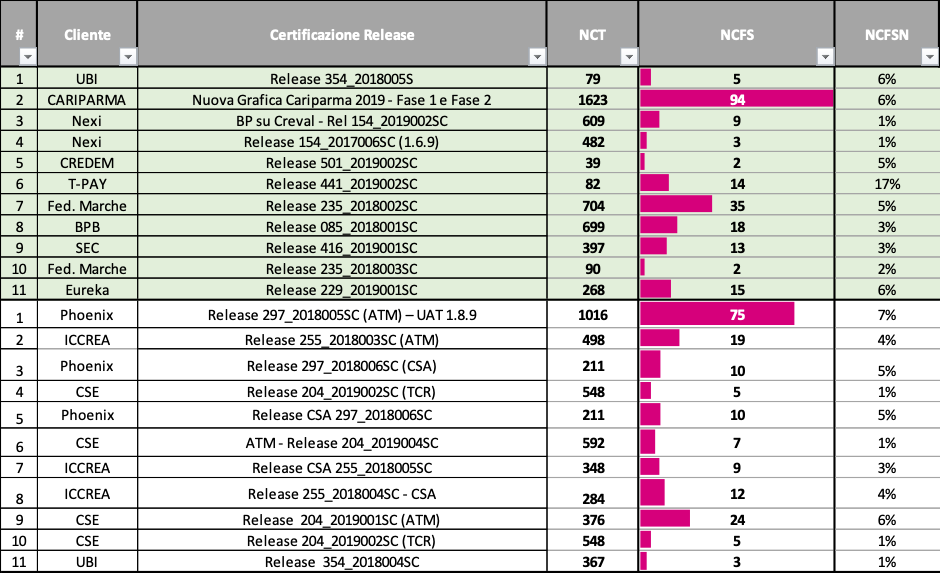
(Figura 3.3. Percentuale di test falliti prima e dopo l’introduzione della V&V)
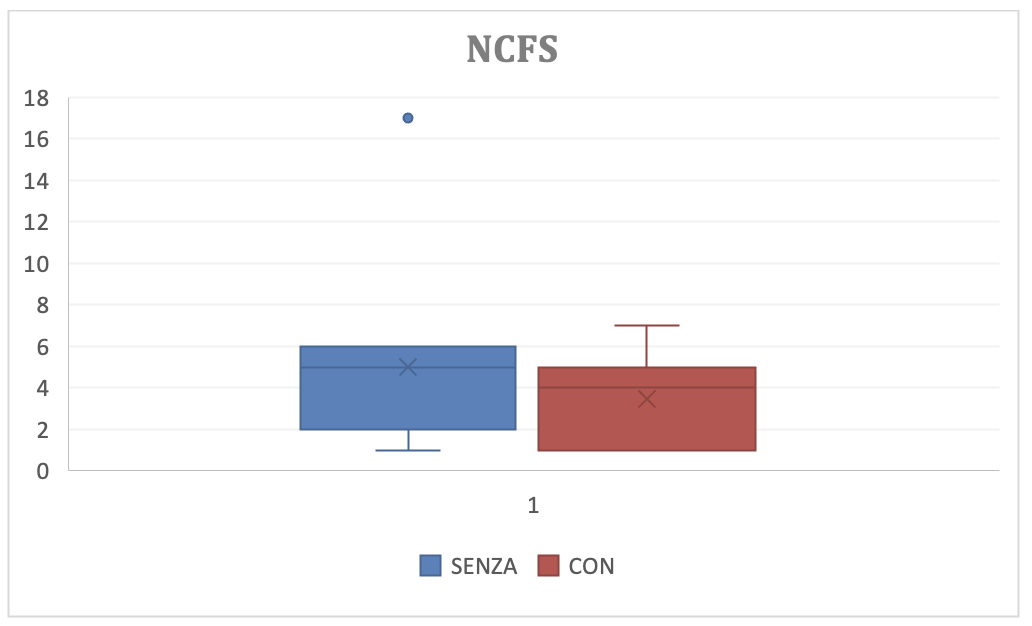 (Figura 3.3-g. Confronto della percentuale di test falliti prima e dopo l’introduzione della V&V)
(Figura 3.3-g. Confronto della percentuale di test falliti prima e dopo l’introduzione della V&V)
Purtroppo non risulta una differenza rilevate tra le due distribuzioni. Questo potrebbe derivare da una carenza di abilità nella V&V e/o da carenza nel processo di sviluppo del software che introduce difetti dalla incoerenza della progettazione rispetto all’analisi e/o della codifica rispetto alla progettazione.
Metodo per il progetto dei test di sistema
Il problema da affrontare è il processo di test, di ogni livello, eseguito in modo non sistematico che comporta le seguenti diseconomie:
- Il numero di casi di test appartenenti al piano non correlati alla complessità dell’entità da testare bensì all’istinto del tester; le conseguenze sono il tempo-persona consumato non è prevedibile la efficacia del test, in termini di fault scoperti risulta carente, quindi la qualità del software consegnato è carente.
- I casi di test non progettati per soddisfare una “politica di copertura” predefinita in AURIGA, pertanto non si può accumulare esperienza per migliorare la “politica di copertura” onde migliorare l’efficacia del test.
- È difficile riusare il patrimonio di casi di test per valutare la regressione.
Q3.5. - IL NUMERO DI CASI DI TEST DI SISTEMA È CORRELATA ALLA COMPLESSITÀ DEL SISTEMA DA CONSEGNARE?
Se il piano di TS è progettato in modo sistematico e rigoroso secondo lo standard introdotto, si dovrebbe verificare che il numero di casi previsti in un piano di test sia correlato alla complessità del sistema realizzato.
Per verificare questa ipotesi sono stati eseguiti 8 casi di studio in cui i piani di TS sono stati progettati secondo l’esperienza dei TAM responsabili dei BRD corrispondenti e 5 casi di studio in cui i piani di TS sono stati progettati secondo lo standard definito a tale scopo. Su ognuno di questi progetti sono stati rilevate le seguenti misure:
Tprog. Tempo necessario per eseguire l’intero progetto. Questo si misura a partire da quando il progetto inizia sino a quando il prodotto è consegnato ed accettato dal cliente. Considerato che si possono assimilare i processi eseguiti per ogni processo, il rapporto tra numero di risorse impiegato e complessità del progetto, il mix di esperienza degli sviluppatori messi in campo, allora, questa misura può esprimere la complessità del progetto.
NCT = il numero di casi di test totali nel piano di sistema.
I risultati sono mostrati in figura 3.4
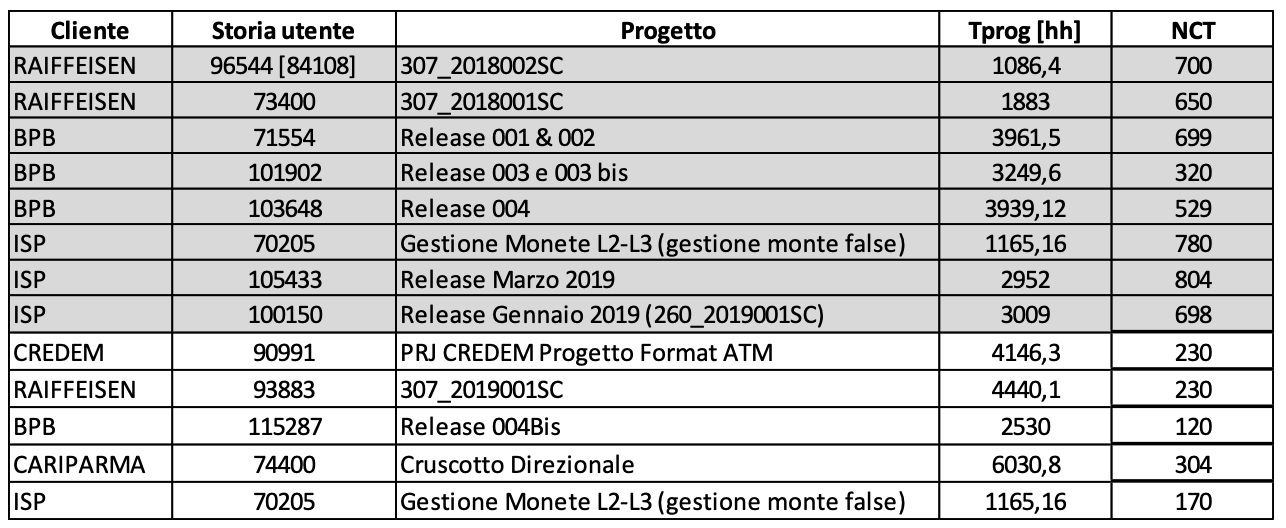 (Figura 3.4. Numero dei casi di test per prodotti di diversa dimensione)
(Figura 3.4. Numero dei casi di test per prodotti di diversa dimensione)
Con i dati rilevati è possibile calcolare due coefficienti di correlazione (R) tra Tprog e NCT per le due classi di casi di studio:
R-senza metodo = 0,14
R-con metodo = 0,86
È evidente che il coefficiente di correlazione che produce l’uso del metodo oltre che essere più significativo di quello che si ha senza applicare il metodo, è anche di buon livello.
Questo risultato vuol dire che il numero di casi nei piani di test progettati sistematicamente (con metodo rigoroso) sono più dipendenti dalla complessità del sistema da testare.
Inoltre, se si osserva la figura 3.4-g, tenendo conto che sino ad 8 sono rappresentati i progetti il cui TS non ha utilizzato metodi formali, mentre da 9 a 13 i progetti che hanno utilizzato il metodo formale introdotto da Auriga, si possono fare due osservazioni:
Sino ad 8 l’andamento della curva di NCT non è coerente con quello della curva di Tprog; mentre i due andamenti sono più coerenti da 9 a 13. Questo è quantificato dal coefficiente di correlazione.
I casi di test utilizzati nei progetti da 1 a 8 sono sempre più alti di quelli utilizzati da 9 a 13, anche quando la complessità dei progetti di questa seconda serie risulta più alta.
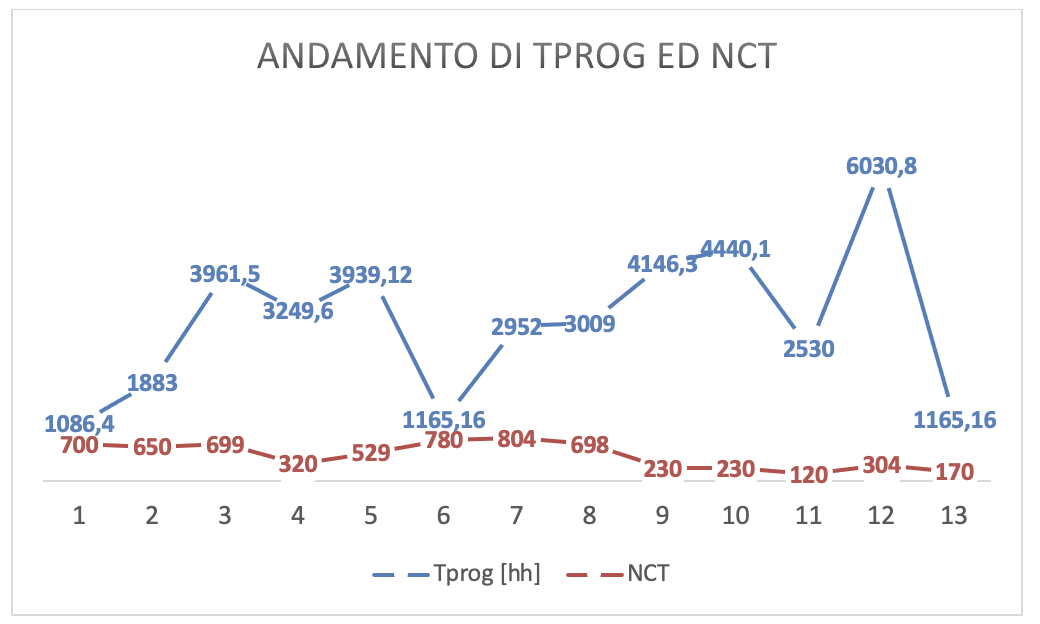 (Figura 3.4-g. Curve di raffronto dei casi di test delle due serie)
(Figura 3.4-g. Curve di raffronto dei casi di test delle due serie)
Dalla seconda osservazione espressa prima si deduce che i piani di TS prodotti con un metodo sistematico sono più economici. La spiegazione di questa affermazione è stata elicitata dagli stessi sviluppatori implicati nella progettazione dei TS: per abbassare il rischio di non rilevare eventuali regressioni verificatisi nel software modificato il progettista tende ad abbondare nei casi di test da effettuare che definisce basandosi sull’esperienza che egli ha per il particolare software.
È opportuno notare che il coefficiente di relazione può essere migliorato. Per realizzare tale miglioramento si ipotizza l’iniziativa di approfondire l’uso del metodo di progettazione del piano di test.
Q3.6 - L’introduzione del metodo aumenta la produttività del test?
L’introduzione del metodo formale per la progettazione del TS dovrebbe far definire i casi di test più significativi dipendentemente dalla struttura e dal contenuto del BRD. Pertanto ci si attende una maggiore produttività del test rispetto ai piani di test progettati senza alcun metodo formale.
Per indagare su questo aspetto sono stati utilizzati gli stessi casi di studio del precedente quesito.
Le misure da rilevare sono:
NB = numero di BUG scoperti durante il TS;
NCT = Numero di casi di Test totali del piano di test di sistema
Si ricava
PT = Produttività del piano di Test= NB/NCT*100. Essendo questo indicatore normalizzato può essere utilizzato nel confronto tra progetti di dimensioni diverse.
I risultati dell’indagine sono riportati in Figura 3.5
 (Figura 3.5. Produttività dei piani di test)
(Figura 3.5. Produttività dei piani di test)
Per analizzare meglio i risultati è stata calcolata la media (figura 5.3) e prodotto il grafico comparativo tra le distribuzioni di produttività (figura 3.5-g).
Il confronto tra le medie mostra che la produttività del TS progettato con il metodo formale è più alta di quello progettato senza metodo formale. La differenza risulterebbe ancora più alta se si eliminassero gli outlier da entrambe le serie che sono dovute alla qualità del particolare sw testato piuttosto che alla qualità del progetto del TS.
Inoltre, il confronto tra le box plot delle due serie di valori della produttività rivela che la serie di valori “con” è meno dispersa della serie “senza”, pertanto si può dire che il metodo formale produce casi di test più mirati.
 (Figura 3.5-g. Box Plot della produttività dei piani di test)
(Figura 3.5-g. Box Plot della produttività dei piani di test)
L’uso del metodo sistematico per il TS assicura maggiore produttività del test perché i casi di test inclusi nel piano sono più mirati a verificare i punti critici del sistema così come si possono rilevare dal BRD. Questo rende più economico la realizzazione dei casi di test e la esecuzione del piano.
La maggiore produttività del test progettato con il metodo sistematico assicura la diminuzione dei difetti lasciati disseminati nel software consegnato e quindi un minor numero di difetti scoperti durante l’esercizio del software. Questo fa diminuire la manutenzione ordinaria del software ed aumenta la qualità avvertita dello stesso software.
Controllo statico del codice
Le conseguenze positive più rilevanti che sono attese con l’uso del controllo statico del codice sono le seguenti:
- Decadimento del codice più lento o addirittura in controtendenza (nel tempo) della qualità del codice. Com’è noto, se non si interviene dall’esterno (tempo uomo per la revisione del codice) con la continua manutenzione la qualità del sw decade nel tempo. Tale decadimento produce diseconomia nel processo di manutenzione ordinaria. Inoltre lo stesso decadimento è avvertito dall’utilizzatore attraverso la rilevazione di maggiore numero di failure in esercizio che, a sua volta, fa diminuire la qualità avvertita e che si traduce in caduta di reputazione con conseguenti danni economici per l’impresa.
- Miglioramento dell’uso del linguaggio secondo le buone pratiche individuate da AURIGA. Le buone pratiche individuate da Auriga costituiscono il modello di qualità su cui KIUWAN basa la sua analisi statica. Ad ogni revisione dell’analisi statica i programmatori hanno rilievi sul loro uso del linguaggio; quindi dovrebbero allineare il loro uso del linguaggio agli standard dell’azienda per far diminuire i rilievi dell’analisi statica.
Un altro risultato atteso dalla verifica statica del codice periodica è la individuazione dei punti critici della qualità del codice per analizzare le cause che lo generano e, quindi, la opportunità di prevedere iniziative di miglioramento dei prodotti allo scopo di alleggerire i processi di manutenzione e migliorare la soddisfazione dei clienti.
Seguono i quesiti posti per osservare queste caratteristiche e le misure rilevate per rispondere ai rispettivi quesiti.
Q3.7 - Come si modifica la qualità dei prodotti?
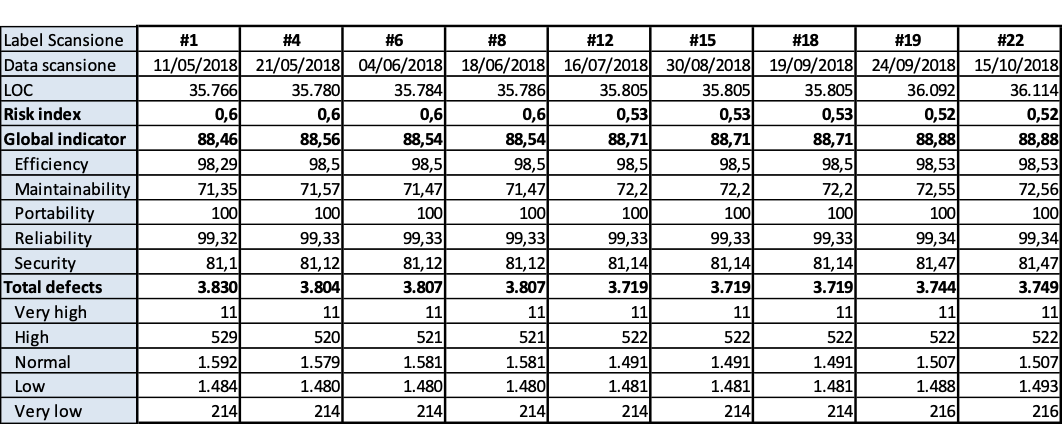
Sono stati utilizzati 10 casi di studio aventi come oggetti osservati altrettanti prodotti. Per ognuno di essi è stato rilevato l’andamento degli indicatori di qualità misurati dal verificatore statico KIUWAN che è stato selezionato da Auriga.
Nell’indagine non è stato dato un metodo formalizzato o rigoroso per decidere come spendere il tempo-persona, bensì è stato lasciato al responsabile del team di sviluppo la decisione delle priorità di superamento degli interventi. Tutti però hanno un time slice fissato dall’impresa da dedicare a queste iniziative per ogni rilevazione. Il time slice cambia nel tempo dipendentemente da quanto l’azienda ha necessità di migliorare la qualità del software.
Non avendo un metodo formale, i responsabili dei team sono guidati dai rilievi di KIUWAN per ottimizzare la produttività del tempo-persona impiegato nel miglioramento della qualità del codice.
L’intervallo di tempo dedicato all’indagine è lo stesso per tutti i prodotti, ma il responsabile del prodotto decide con quale frequenza fare la rilevazione statica, sulla base di quanta manutenzione lo stesso prodotto ha subito. Questo sempre nello spirito di economizzare a parità di risultato sul miglioramento della qualità.
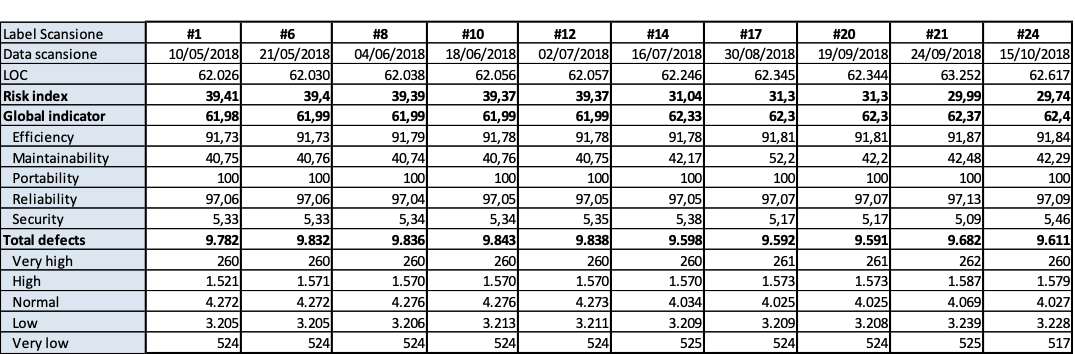
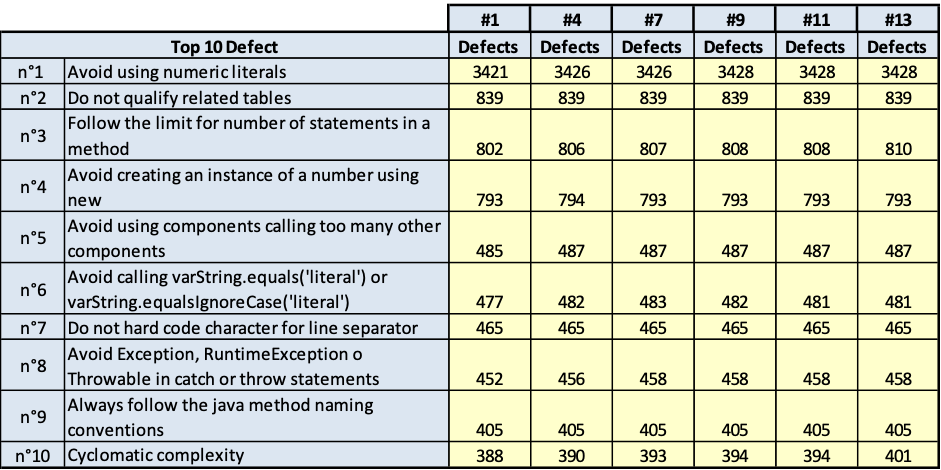
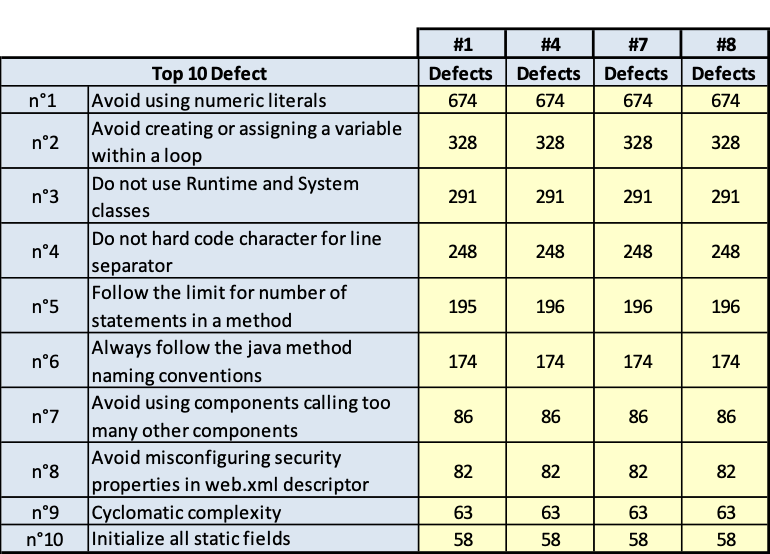
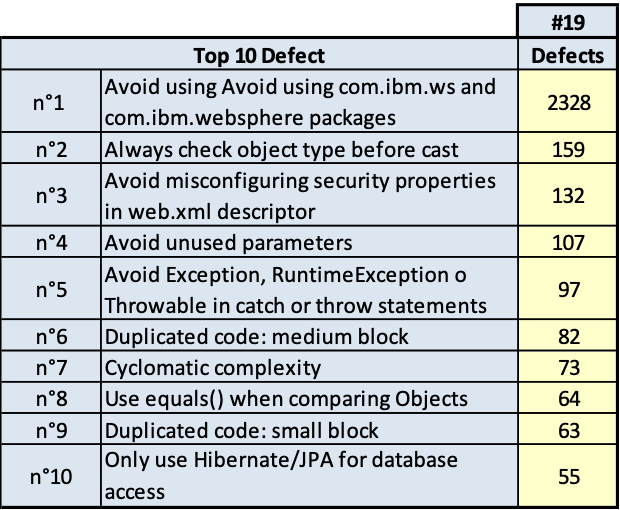
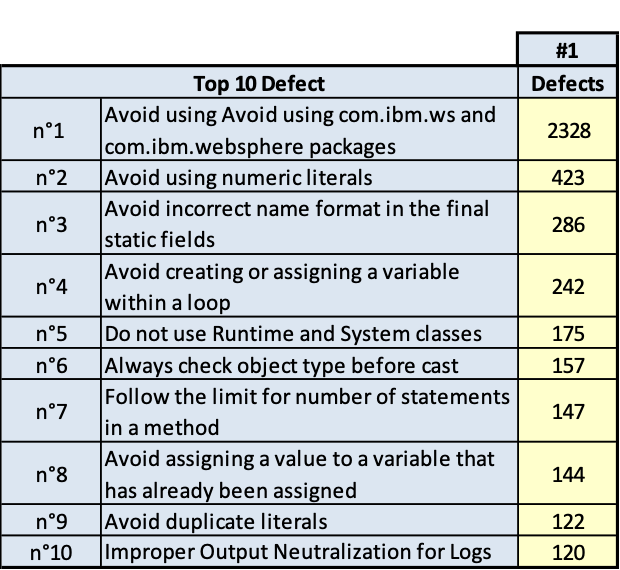
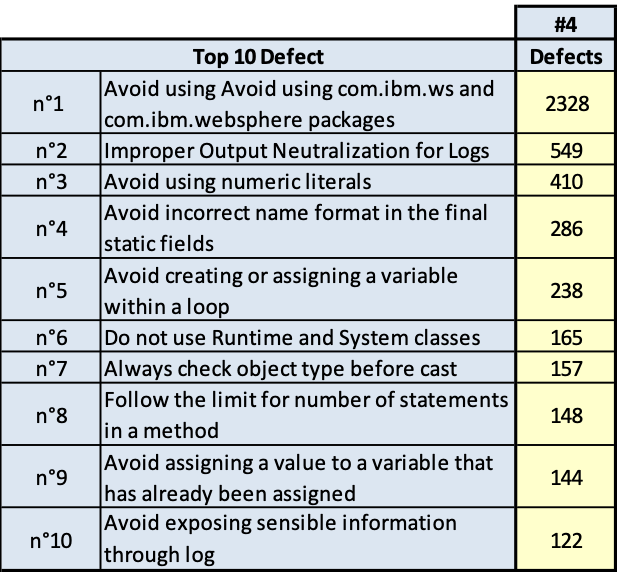
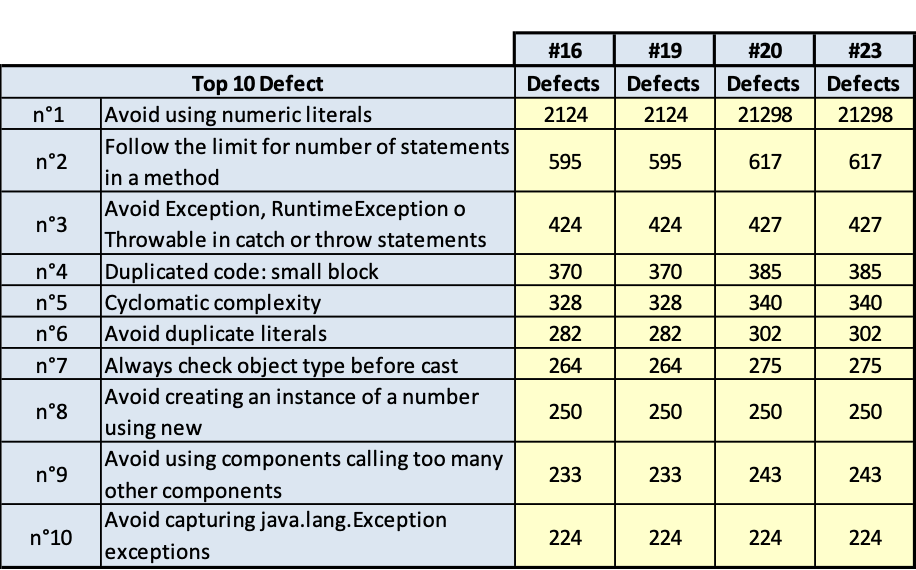
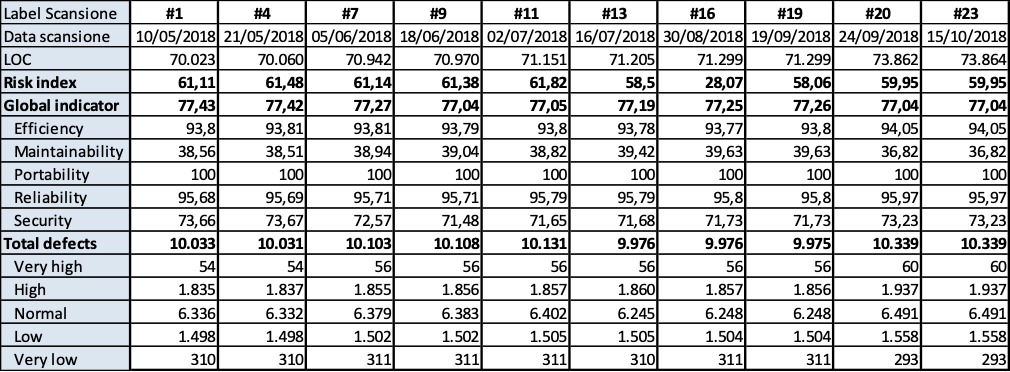
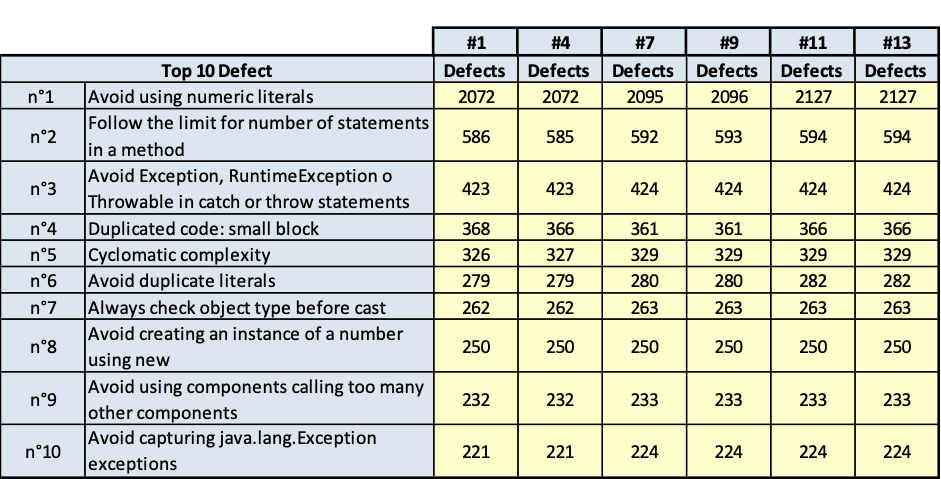
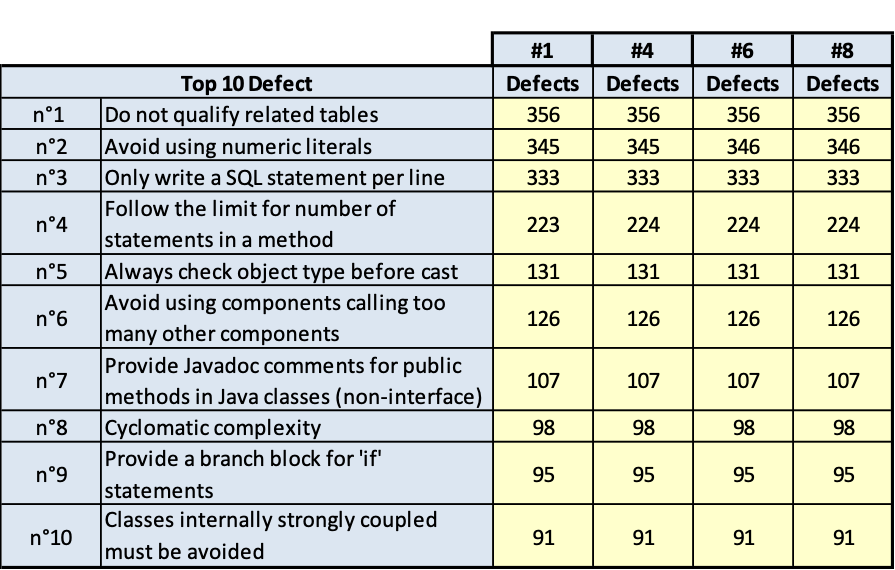
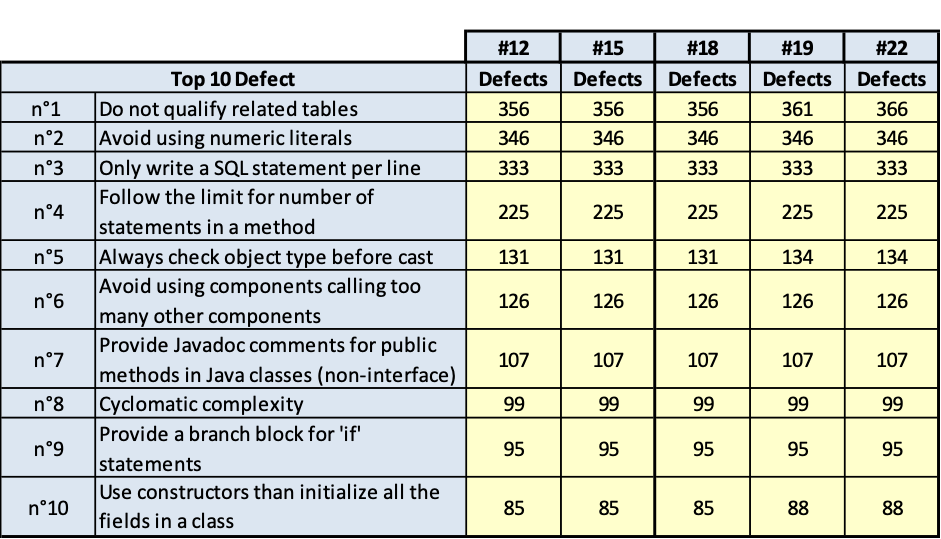
I risultati sono riportati nelle tavole da 3.6 a 3.15, ogni figura è inerente il rispettivo prodotto indicato. Le tavole sono divise, per maggiore leggibilità, in sotto tavole che mostrano l’andamento degli indicatori nel tempo e i 10 difetti risultati più numerosi nel tempo. Per chiarezza, si fa presente che il numero di etichetta presenti nelle tavole dichiara il numero di rilevazione eseguita; le rilevazioni sono esposte in ordine cronologico per poter rispondere meglio al quesito.
ABASv2

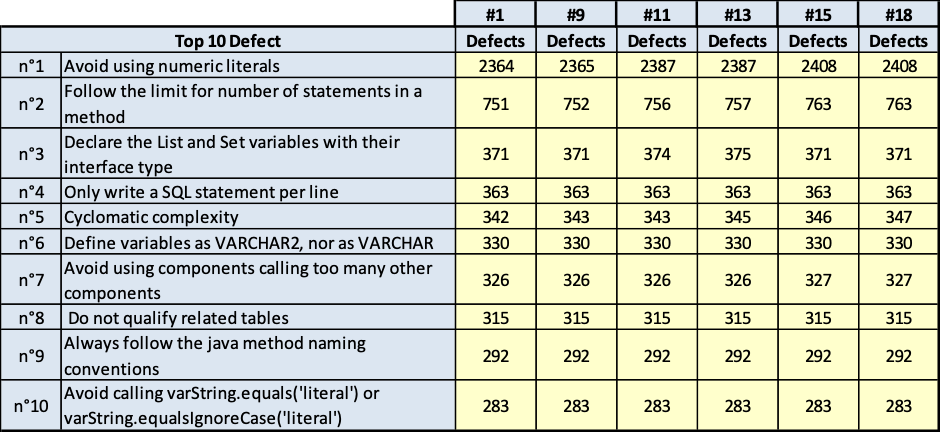
Fig.3.6.a. Fig. 3.6.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi

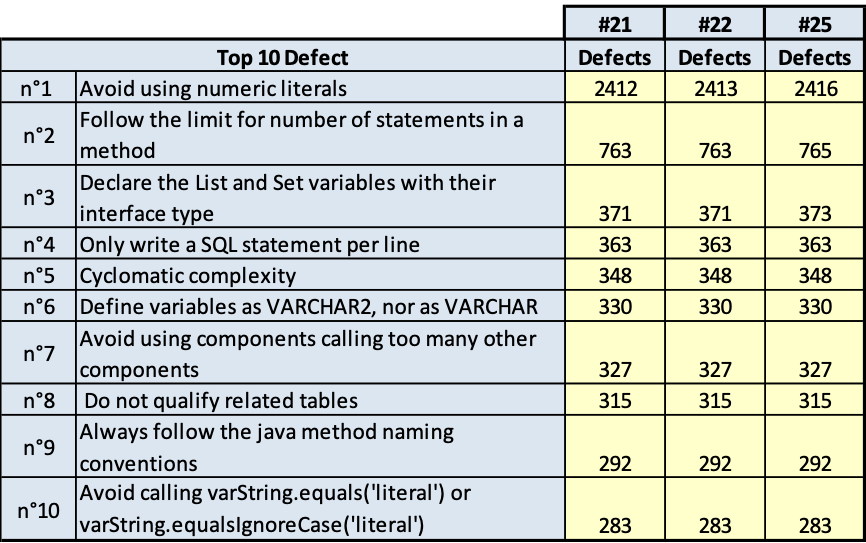
Fig.3.6.c. Fig. 3.6.d.. Andamento della qualità e consistenza dei 10 difetti più numerosi
SSBEv2 Base
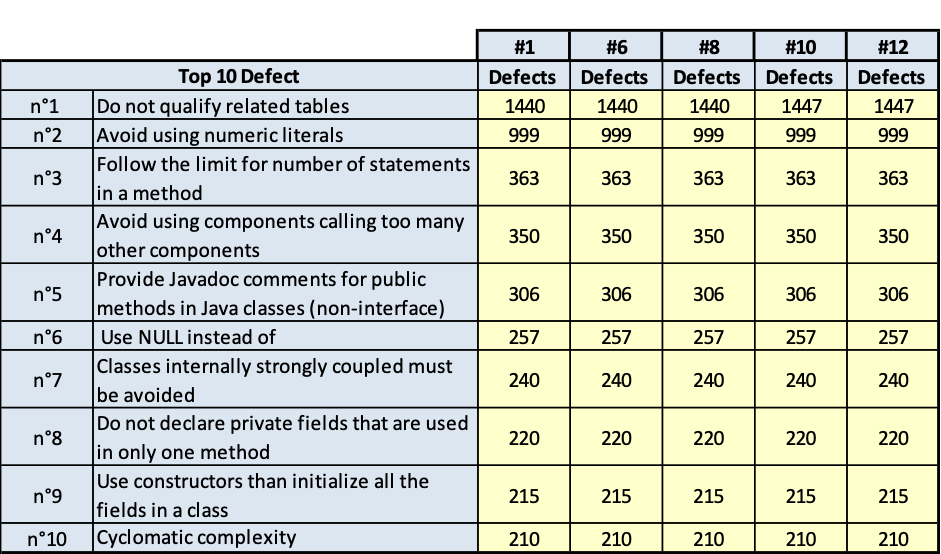
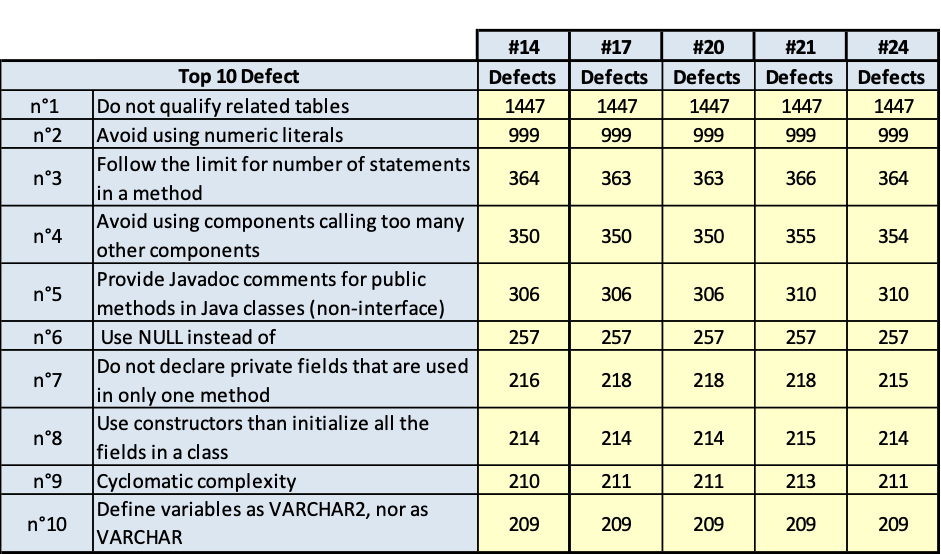
(Fig.3.7.a. Fig. 3.7.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
(Fig.3.7.c. Fig. 3.7.d.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
Auriga Base Web App
(Fig.3.8.a. Fig. 3.8.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
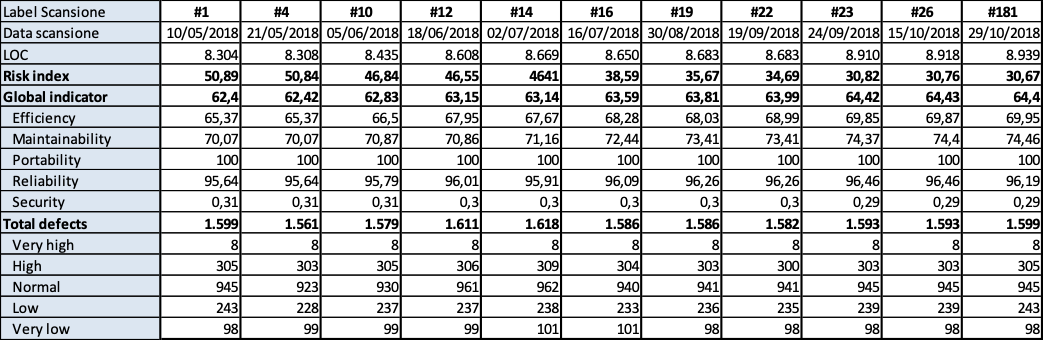
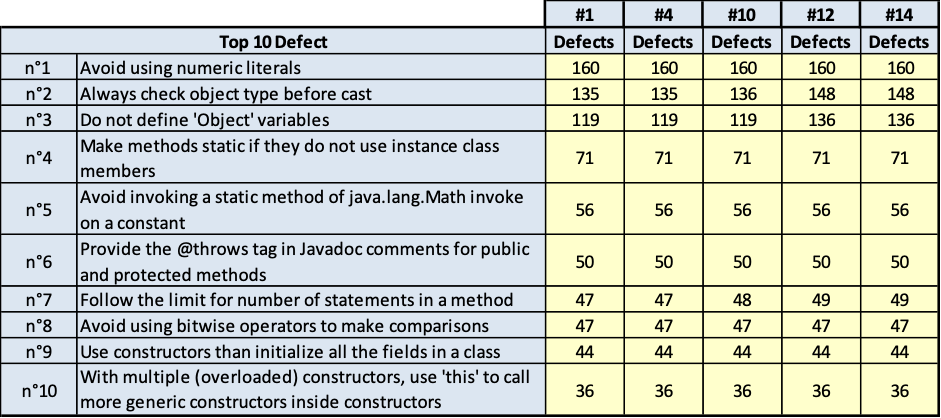
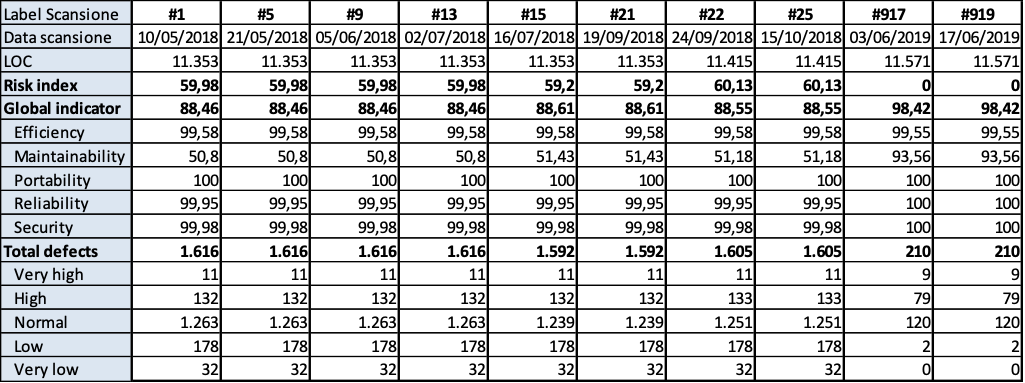
Auriga core
(Fig.3.9.a. Fig. 3.9.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
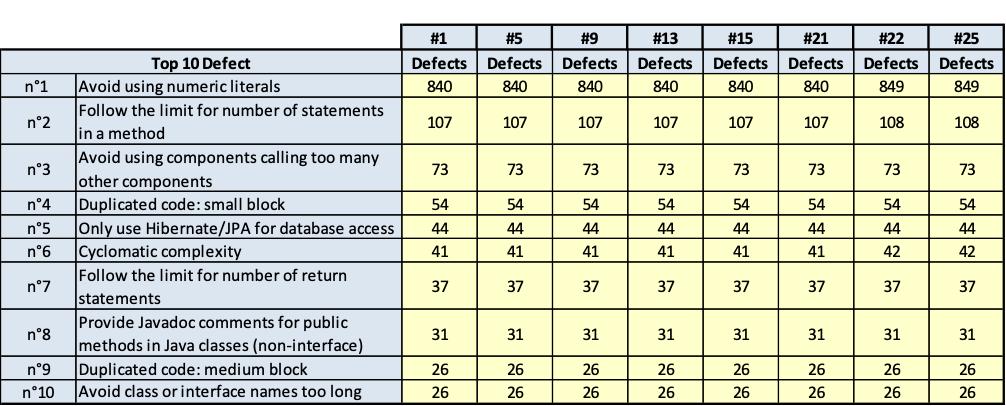
HBASv4
(Fig.3.10.a. Fig. 3.10.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
AMS
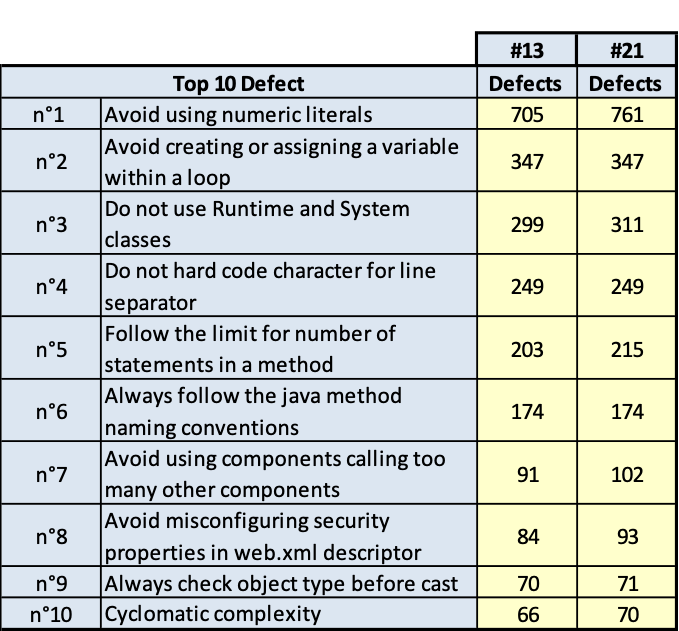
(Fig.3.11.a. Fig. 3.11.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
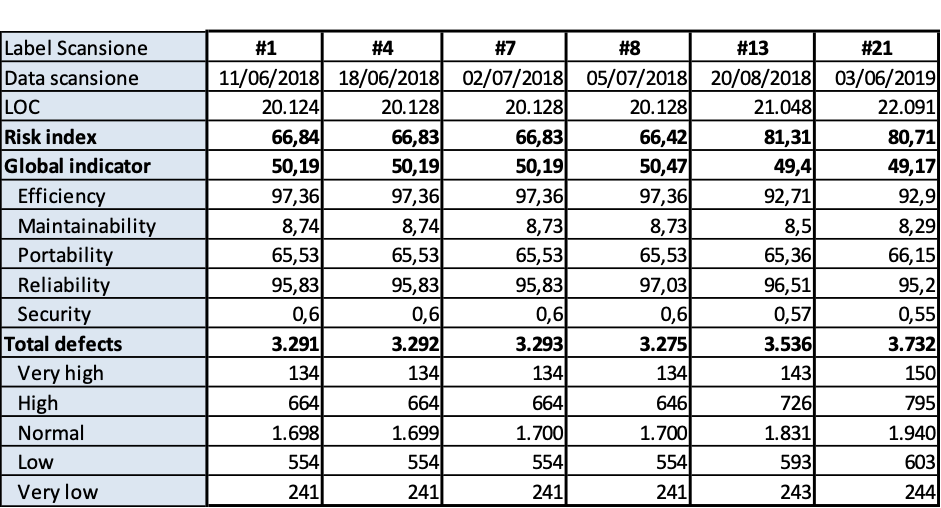
Download manager
(Fig.3.12.a. Fig. 3.12.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)

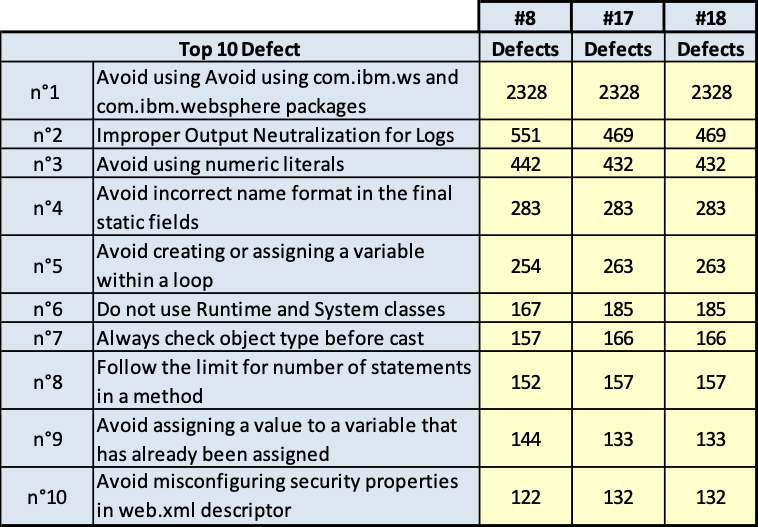
ACTIVE
(Fig.3.13.a. Fig. 3.13.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
WIRE ISP
(Fig.3.14.a. Fig. 3.14.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
PLMA

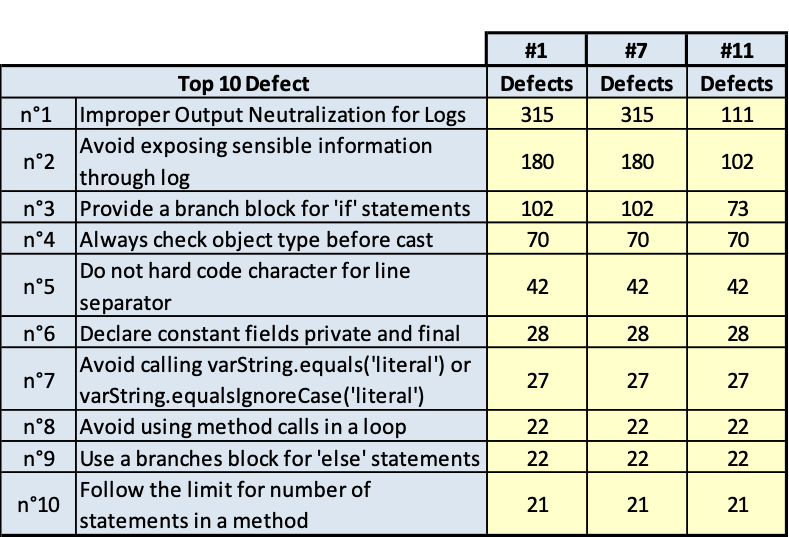
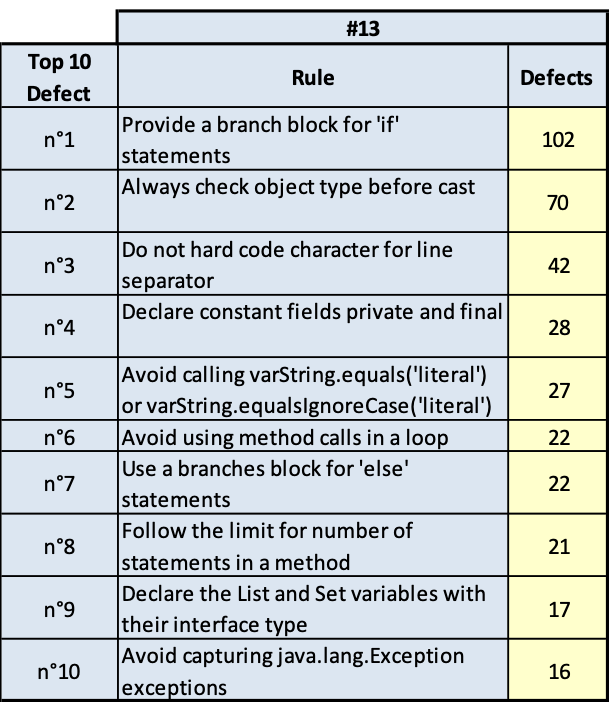
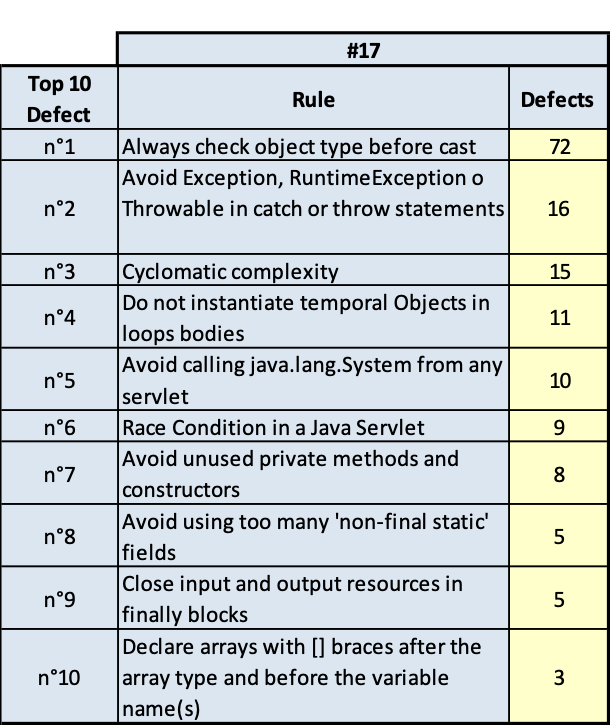
(Fig.3.15.a. Fig. 3.15.b.. Andamento della qualità e consistenza dei 10 difetti più numerosi)
Dall’analisi delle tavole precedenti è evidente che ci sono essenzialmente due classi di rilievi:
- quelli derivati dallo stile di scrittura dei programmi; per esempio: uso di numeric literal; molti statement in una stessa linea di codice; VARCHAR invece di VARCHAR2;
- quelli dovuti alla struttura del codice; per esempio: complessità ciclomatica, catena di chiamate lunga.
È evidente che la prima classe di rilievi è più facilmente superabile, la seconda classe di rilievi è meno facilmente superabile per la difficoltà della ristrutturazione del codice e per gli effetti collaterale che tale ristrutturazione può avere. La ristrutturazione di questa seconda classe di rilievi comporta spesso la modifica alla progettazione del software, quindi diventa molta onerosa. Però, quest’ultima classe di rilievi fa emergere anche qualche difficoltà anche sulla progettazione dei casi di test e quindi anche sulla probabilità di lasciare disseminato nel software qualche fault che emergerà come malfunzionamento durante l’esercizio del software in un tempo indeterminabile.

(Figura 13.16.a. Grafico dei valori degli indicatori di qualità)

(Figura 13.16.b. Grafico dei valori degli indicatori di qualità e di complessità ciclomatica)
Per fare qualche considerazione approfondita, onde rispondere esaurientemente al quesito posto, in figura 3.16.a sono mostrati i grafici dei valori dei due indicatori (per rendere leggibile il grafico) ritenuti i più critici per Auriga: indicatore globale di qualità e l’indicatore di manutenibilità. Per ogni indicatore è mostrato il suo valore alla prima rilevazione “DA” e quello all’ultima rilevazione “A”. mostrando così una sintesi dell’andamento della qualità nel tempo di osservazione dell’indagine. Dalla lettura del grafico si evince che il decadimento della qualità del codice è fermato, quando c’è è irrilevante, e nella gran parte dei casi c’è un miglioramento rilevante. Ne segue che la verifica statica del codice periodica favorisce la individuazione dei punti critici della qualità del codice e la previsione delle iniziative di miglioramento dei prodotti allo scopo di alleggerire i processi di manutenzione e migliorare la soddisfazione dei clienti.
In figura 13.6.b è sovrapposto ai due indicatori della figura precedente quello della complessità ciclomatica, quando appare tra i primi 10 più frequenti rilievi. Qui è da rilevare che tranne in un caso la complessità ciclomatica è un rilievo che appare sempre tra i primi 10 rilievi più frequenti, in tutto il periodo di indagine. Inoltre si rileva che il numero di rilievi di questo tipo è considerevole in tutti i programmi.
Per un altro punto di vista sulla stessa analisi

(Figura 13.6c. Variazioni degli indicatori con gli interventi dei programmatori)
Nella tavola sono mostrati per ogni prodotto:
- RILAVORAZIONI: numero di rilavorazioni che per ogni prodotto sono state eseguite per contrastare il decadimento della qualità e per migliorarlo.
CAMBIAMENTI: quante volte sono cambiati i top 10 rilievi a seguito delle rilavorazioni.
Δ INDICE GLOBALE: la variazione dell’indice globale di qualità dall’inizio alla fine dell’indagine, questo quantifica esattamente il decadimento o il miglioramento della qualità, a seguito degli interventi di rilavorazione.
Δ IND. MANUTENZ.: la variazione dell’indice di manutenzione dall’inizio alla fine dell’indagine, questo quantifica esattamente il decadimento o il miglioramento della manutenibilità, a seguito degli interventi di rilavorazione.
Δ COMPLESS. CICL.: questo quantifica la variazione del numero di rilievi per complessità ciclomatica che si hanno nel periodo di indagine a seguito delle rilavorazioni effettuate.
Si rileva che per tutti i prodotti le attività di miglioramento della qualità hanno cambiato anche più volte la lista dei rilievi più numerosi. Questo significa che la decisione su come spendere l’impegno persona per il miglioramento è efficacemente supportata dallo stesso strumento di analisi statica del codice.
Si conferma che laddove c’è decadimento di qualità questa è irrilevante, quindi se decadimento c’è questo è rallentato. Altresì l’efficacia degli interventi indotti dall’analisi statica del codice si rileva con l’aumento frequente e considerevole della qualità del codice.
Il numero di rilievi, in ogni prodotto, di complessità ciclomatica è in genere stabile o in aumento, qualche volta anche considerevolmente. Fa eccezione solo AURIGA CORE dove il numero di rilievi di questo tipo sono diminuiti di 36 punti. Ma questo è dovuto alla decisione di riscrivere il prodotto. concludendo: i difetti strutturali sono i più complessi e costosi da superare e frequentemente richiedono dei piani di ristrutturazione del codice che parta dalla corrispondente progettazione del sistema. Il beneficio che porta questo notevole costo è un notevole miglioramento della qualità del sistema ed in particolare della sua manutenibilità.
Q3.8 - Come si modifica l’uso del linguaggio nelle applicazioni?
I casi di studio in questo caso sono sempre progetti di Auriga.
È atteso che il numero di rilievi sul prodotto di un programmatore diminuiscano perché quest’ultimo ha appreso le pratiche di codifica più sensibili per Auriga. Inoltre lo stesso programmatore deve avere una distribuzione di rilievi sempre diversa: nella lista top 10 dei rilievi più numerosi devono gradualmente sparire i rilievi che attengono agli standard più critici, per inerenti le applicazioni più frequenti del linguaggio. Questo dimostrerebbe che il programmatore apprende sempre meglio gli standard d’uso di Auriga, attraverso le regole del modello di qualità impostate in KIUWAN.
L’indagine è eseguita con 15 sviluppatori come soggetti sperimentali. Ognuno è sottoposto a più prove. Ogni prova consiste di un modulo di un prodotto, di diversa dimensione e complessità, su cui il soggetto deve operare delle modifiche e nel contempo deve migliorare la qualità del prodotto secondo gli indicatori di KIUWAN. Il tempo-persona che uno sviluppatore può impiegare per la modifica è definito attraverso la negoziazione con il responsabile del team di sviluppo, secondo la esperienza di entrambi. Il tempo-persona da dedicare al miglioramento del codice è sempre il 10% di quello dedicato alla modifica. Tutti gli oggetti sperimentali sono programmi codificati in java. L’indagine si svolge in un predefinito periodo per cui, dipendentemente dall’occupazione del soggetto sperimentale, ognuno di loro ha eseguito un numero diverso di prove. (minimo 2, massimo 9).
Gli sviluppatori, per riservatezza, sono, come al solito, citati per codice.
Per ogni sviluppatore e per ogni prova eseguita sono rilevati sia la variazione degli indicatori di qualità del prodotto che gli è stato assegnato di codificare sia come cambiano i 10 difetti più numerosi rilevati. I dati rilevati sono riportati da figura 3.17 a figura 3.31. Anche in questo caso ogni figura è divisa in sotto tavole per renderle più leggibili.
Dalla lettura di queste figure la prima osservazione è che la lista dei top 10 rilievi più numerosi cambia in ogni prova. Questo dimostra che il programmatore si conforma sempre meglio agli standard d’uso del linguaggio definiti in Auriga. Inoltre si rileva che in alcune prove non ci sono 10 classi di rilievi, questo significa che i programmatori tendono ad acquisire lo standard d’uso del linguaggio sino ad azzerare i rilievi. Questo risultato ha un rilevante riverbero sulla economicità della codifica.
Per analizzare meglio i risultati dell’indagine in figura 3.32 sono riportati per ogni prova e per ogni sviluppatore le misure:
Na: numero di rilievi totali del modulo modificato, in percento = Numero-di-rilievi-totali /Numero-di-LOC *100
Nb: numero di rilievi totali del modulo migliorato, in percento = Numero-di-rilievi-totali /Numero-di-LOC *100
Visualizza i dati relativi alle modifiche della qualità su prodotti diversi assegnati allo sviluppatore e della consistenza dei 10 difetti più numerosi.
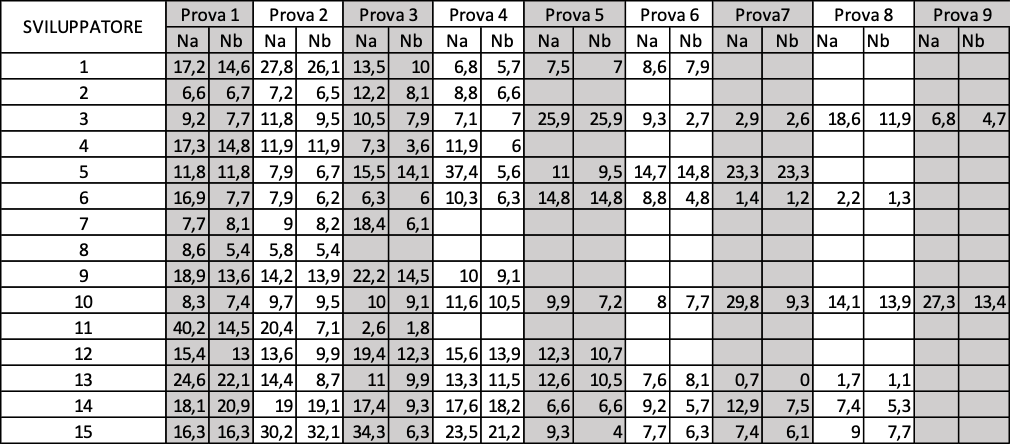
Figura 3.32. Numero di rilievi nelle prove dei 15 soggetti sperimentali
I valori di questa figura sono rappresentati graficamente nei nove grafici seguenti: 1 per ogni prova. Per poterli analizzare più chiaramente.
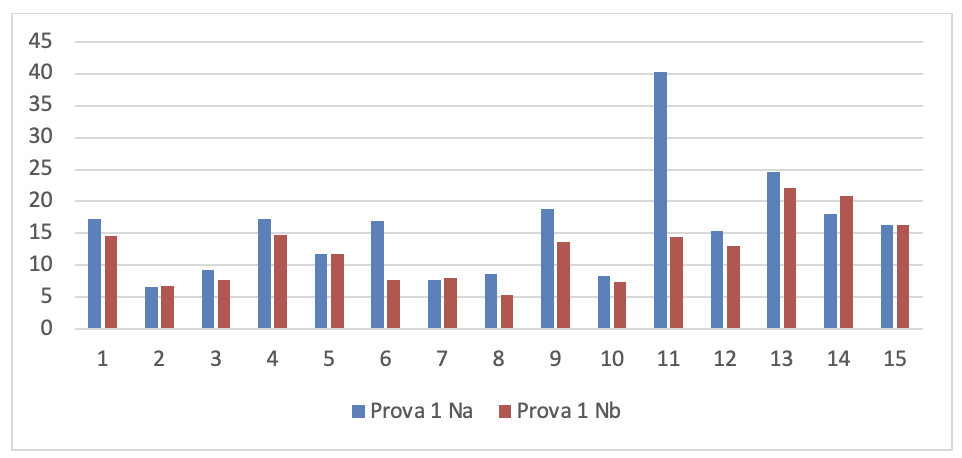
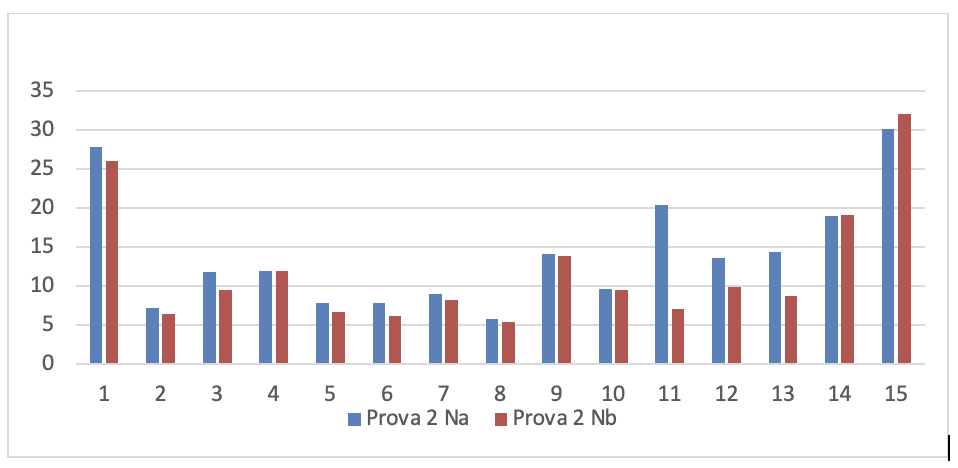
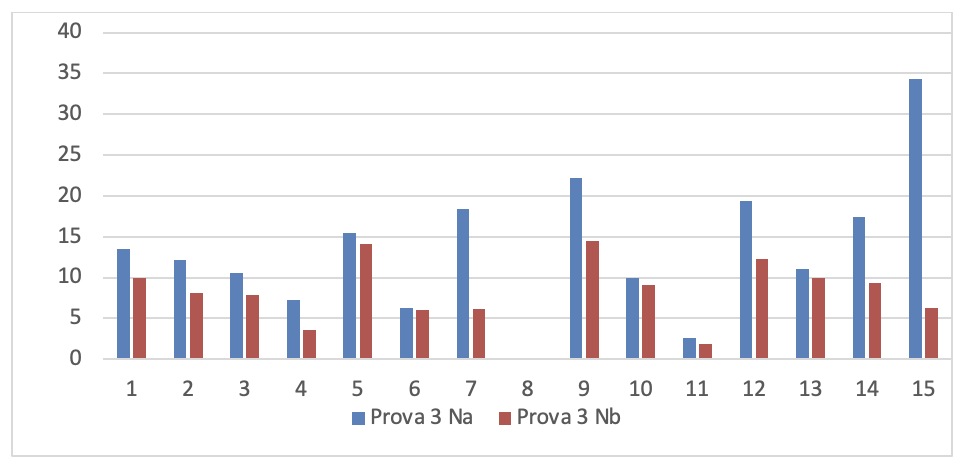
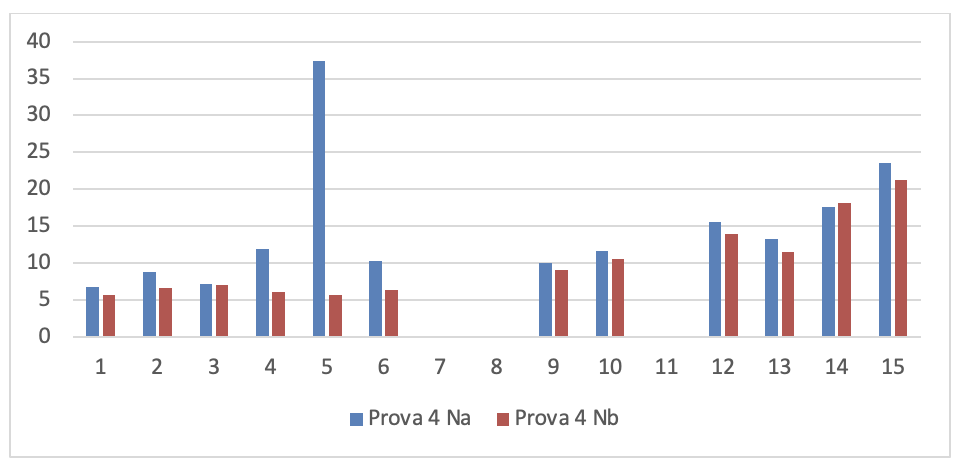
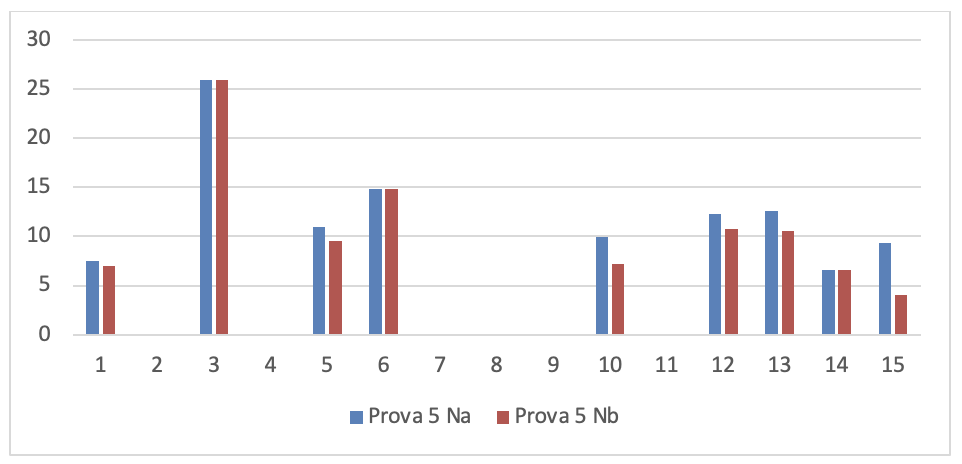
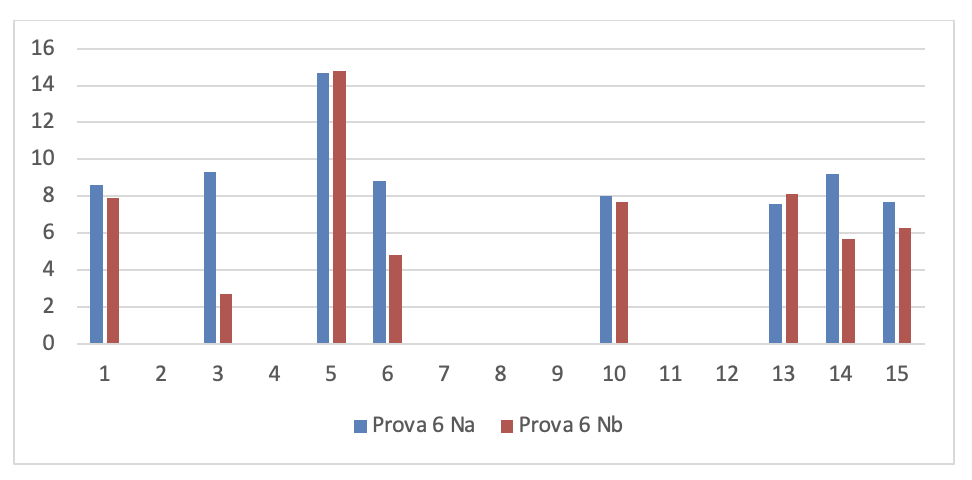
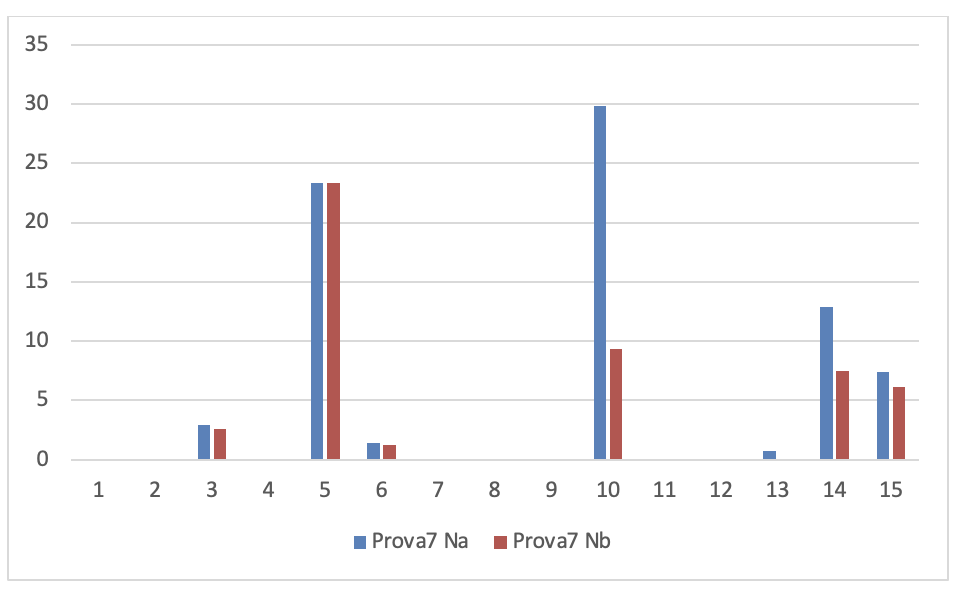
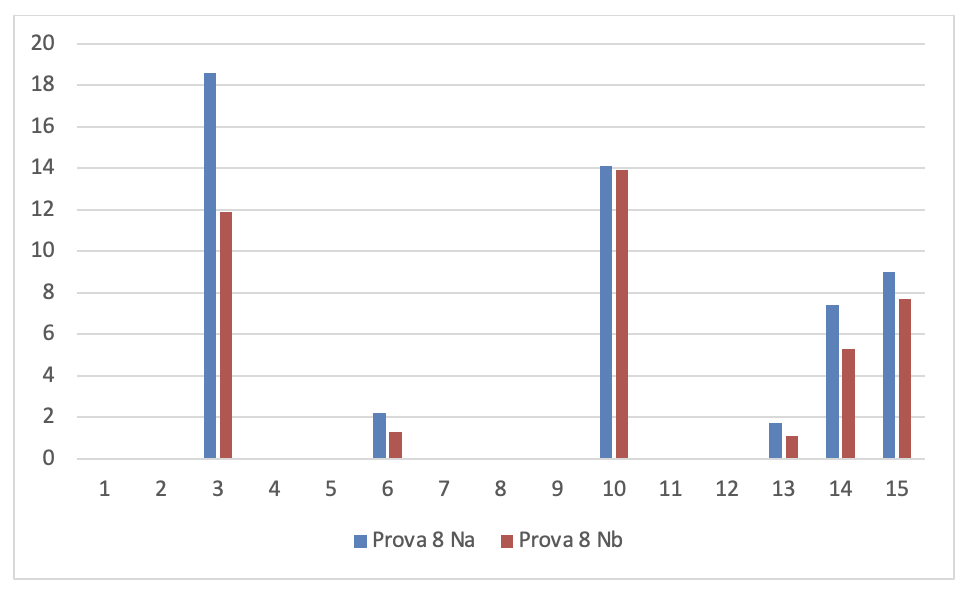
- Dati progetti TFS per la serie di controllo
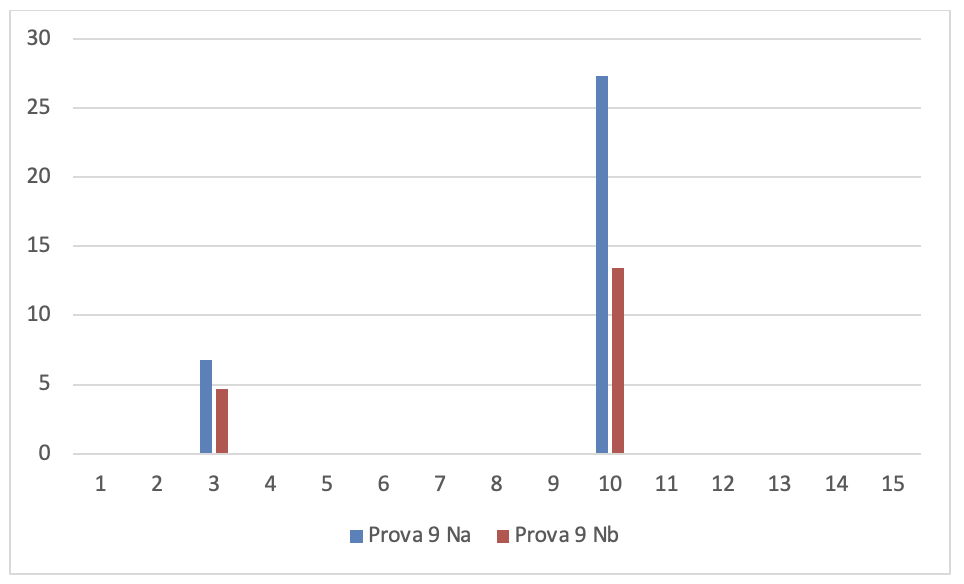
Se si leggono i risultati dei 15 soggetti sperimentali su ogni grafico si evince che tutti i programmatori sono in grado di migliorare anche considerevolmente il numero dei rilievi emersi dall’analisi statica del codice dopo aver fatto gli interventi migliorativi, tranne che in alcuni casi. La spiegazione di queste eccezioni è esposta nel prossimo capoverso.
Se si leggono verticalmente, tenendo conto che l’ordine delle prove è cronologico, si rileva che lo stesso soggetto sperimentale in prove diverse ha una performance diversa e che questa qualche volta peggiora nonostante il programmatore abbia acquisito maggiore esperienza sull’uso del linguaggio. Questo si può spiegare solo tenendo conto che la prestazione dello sviluppatore non dipende solo dalla sua abilità ma anche dal prodotto che deve migliorare. In particolare è la complessità del prodotto che modera la prestazione del programmatore.
Quest’ultima considerazione richiama quanto detto nel quesito precedente: la complessità della struttura dei programmi riverbera su altri aspetti della qualità.
Qualità dei processi
Per l’obiettivo olistico di AURIGA 2020 è essenziale analizzare quanto i processi produttivi attualmente eseguiti siano conformi allo standard di riferimento così che si possa valutare quanto la disciplina definita in questo programma per la esecuzione del processo guidata dal TFS (TR4.1) e gli standard di processo (TR3.1) siano migliorativi.
La esecuzione conforme consente di rilevare sistematicamente misure su ogni attività così che si possano comprendere pregi e difetti dei modelli di processo definiti. Questi ultimi devono essere indipendenti da chi li esegue e dall’ambiente in cui si eseguono così che debbano servire a comprendere le caratteristiche, positive o negative, concernenti esclusivamente i modelli dei processi. Una volta impostate le misure più significative per la misura dei processi si possono individuare tempestivamente eventuali punti da migliorare per eliminare gli sprechi e determinare iniziative di miglioramento che possano essere applicate a tutti i processi che si eseguono in AURIGA.
In prima istanza confrontiamo i processi che si eseguono attualmente rispetto ai processi disciplinati come progettato in AURIGA 2020 con il proposito di analizzare la conformità dei processi e la prevedibilità dei processi. La conformità è la condizione necessaria perché i processi possano essere misurati. La prevedibilità dei tempi di esecuzione dei processi è quanto serve per poter individuare eventuali sprechi.
Q3.9 - Qual è il livello di conformità dell’esecuzione dei processi?
La misura necessaria è:
NR = numero di rilievi alla conformità di esecuzione dei processi
La misurazione si è applicata su un insieme di progetti divisi in due classi: progetti eseguiti secondo il metodo consueto, processi eseguiti dopo aver riformato i modelli in TFS. La prima classe di progetto costituisce l’insieme di controllo. La seconda classe di progetti è l’insieme sperimentale delle nuove regole.
La prima classe è costituita da 16 progetti TFS, senza i vincoli di disciplina previsti in AURIGA 2020. Sono stati selezionati esclusivamente progetti in stato “Completato”.
Il numero di rilievi totali individuati nei 16 progetti è:
NR = 91
Di seguito sono riportati il numero medio di rilievi per progetto, il numero di rilievi minimo e massimo per progetto:
NR(media) = 6
NR(min) =3
NR(max) = 8
Per poter contare il numero è stato necessario elicitare i possibili rilievi. La lista di rilievi elicitata potrebbe non essere esaustiva ma la riteniamo affidabile perché i progetti selezionati sono ritenuti un campione significativo degli sviluppi software normalmente eseguiti in Auriga.
I tipi di rilievo che sono stati inventariati sono i seguenti:
- Coordinamento: manca l’attività di coordinamento.
- Distribuzione: manca l’attività di distribuzione.
- Documentazione: Manca l’attività di produzione della documentazione che deve accompagnare il software alla consegna.
- Project Management: è assente l’attività di project management.
- Analisi funzionale: manca l’attività per la produzione dell’analisi funzionale.
- Progettazione: manca l’attività per la produzione della progettazione del software da realizzare.
- Source control: manca l’attività di source control.
- Test: manca l’attività di test di sistema e di accettazione da parte dell’utente.
- Attività non prevista: attività non prevista nello standard di processo adottato.
- Attività anticipata: attività fuori dalla sequenza prevista dal modello di processo adottato ed eseguita in anticipo (per esempio l’esecuzione della documentazione prima della progettazione, dello sviluppo e del test).
- Attività posticipata: attività fuori dalla sequenza prevista dal modello di processo adottato ed eseguita in posticipo (per esempio: il progetto dopo la codifica).
Circa questi rilievi possono essere fatte le seguenti considerazioni, sempre puntando allo scopo delle misurazioni che si stanno effettuando:
- I rilevi dalla “a” alla “d” evidenziano difetti di registrazione nel TFS. Infatti non è possibile che non siano state fatte queste attività perché il coordinamento, il p.m., la distribuzione e la documentazione sono attività certamente eseguite perché altrimenti il progetto non poteva andare avanti e non poteva essere considerato concluso. Pertanto questo significa che il tempo-persona consumato in queste attività è stato imputato ad altre attività. Questi difetti quindi non danno la possibilità di valutare i costi reali di ogni attività; ovvero non si può comprendere quali attività hanno potenziali problemi di spreco né si può rendere il processo precedibile nei costi e nei tempi di esecuzione.
- I rilievi da “e” ad “h” potrebbero essere causati da carenze di registrazione su TFS, in tal caso ricadrebbero negli stessi problemi visti prima; ma, più probabilmente, sono difetti di esecuzione dei processi e questi potrebbero portare a seri problemi di qualità della documentazione tecnica (BRD, SDS) e del prodotto consegnato. I problemi nella documentazione tecnica è generatore di enorme spreco: se la documentazione tecnica non è sincrona con il comportamento del codice diventa inutilizzabile, quindi, si è sprecato tutto il tempo-persona speso per la produzione dell’attuale documentazione tecnica; se il prodotto consegnato non è di buona qualità la probabilità che si verifichino malfunzionamenti in esercizio diventa più alta; quindi più alto il costo per riparare i difetti disseminati nel codice e diminuisce la qualità avvertita dall’utilizzatore del software.
- Il rilevo “I” è sicuramente una fonte di spreco.
- I rilievi “j”, “k” potrebbero essere dovuti ad errori di registrazione, in tal caso ricadono nelle considerazioni esposte al primo punto, ma, più probabilmente possono essere gravi errori di conformità che potrebbero portare ai problemi analizzati nel secondo punto.
Da quanto detto, I rilievi elicitati hanno fatto emergere delle carenze nella modalità di registrazione delle attività, di conseguenza, è stato necessario intervenire diffondendo delle direttive a riguardo. Di seguito alcune delle direttive, presenti nel Manuale con Linee Guida e Buone Pratiche per il consuntivo dei Work-Item su TFS al fine di tenere traccia dello stato di avanzamento effettivo delle attività, che sono state fornite alla fabbrica:
- Verificare che la tipologia di attività del work-item assegnato sia congruente all’effettivo lavoro richiesto nella creazione dei work-item è importante associare le ore lavorate al corretto centro di costo, facendo in modo che vi sia una corretta corrispondenza tra il codice cliente ed il codice commessa di riferimento
- Accertarsi sempre di essere gli assegnatari del work-item prima di imputare le ore di Lavoro svolto
- Nell’utilizzo della funzionalità di duplicazione del work-item è necessario svuotare sempre tutti i campi “Stima originale”, “Tot. ore rimanenti”, Tot. ore lavorate, “Lavoro Svolto” dopo di che salvare e chiudere il work-item. Riaprirlo per effettuare l’imputazione delle ore lavoro svolto
- A ciascun utente appartiene il singolo work-item su cui consuntivare il proprio lavoro, non bisogna prendere in carico un work-item assegnato ad un altro utente se vi sono già ore loggate da quest’ultimo
- se l’attività assegnata è avviata, lo stato della task TFS di riferimento deve essere aggiornato con il valore “Attivo”
- se l’attività assegnata è stata conclusa, lo stato del Task TFS di riferimento deve essere aggiornato con il valore “Chiuso”. Questo prescinde dall’aver esaurito il monte ore stimato per l’attività
- se l’attività è stata messa in stato sospeso a causa dell’impossibilità di concluderla e non ci sono ulteriori ore da consuntivare, lo stato del task TFS di riferimento deve essere aggiornato con il valore “Nuovo”, descrivendo nella sezione “Cronologia” le motivazioni dell’interruzione.
Un’analisi dell’impatto delle precedenti direttive potrà essere effettuata solo quando i progetti attualmente in corso verranno completati.
Per sperimentazione si sono eseguiti 4 progetti con i modelli di processo definiti in AURIGA 2020 e con i vincoli al TFS previsti in questo stesso programma e sono risultati zero rilievi.
Q3.10 - Come si distribuiscono i rilievi per tipo di non conformità?
La misura necessaria è:
NTR = numero per tipo di rilievo.
La figura 3.33 mostra la tipologia di rilievi effettuati ed il numero degli stessi sui 16 progetti TFS analizzati. Il dettaglio dei rilievi nei progetti analizzati sono riportati in figura 3.34.
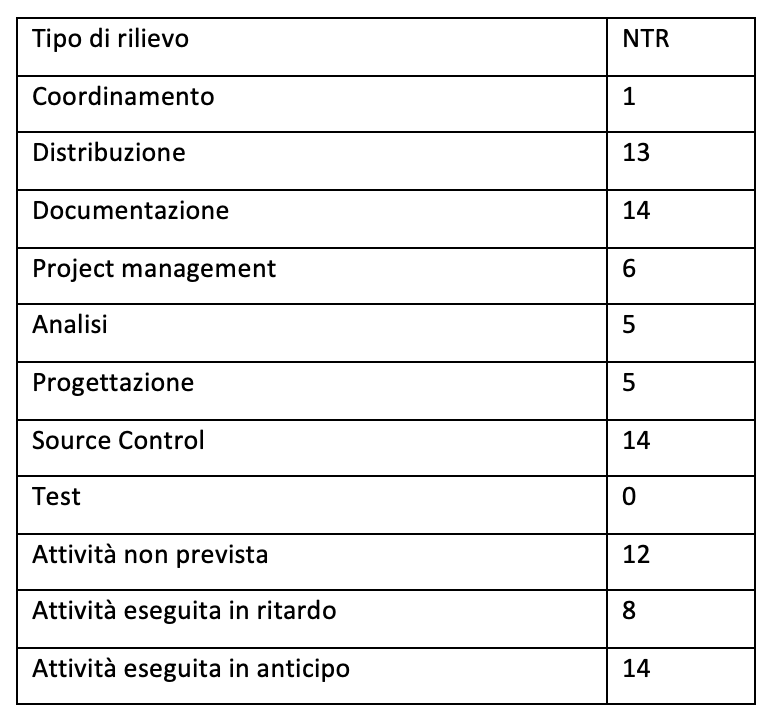
(Distribuzione dei rilievi per tipo)
Tenuto conto delle considerazioni fatte prima, dalla distribuzione dei rilievi per tipo è evidente che ci sono molti margini di miglioramento nell’economia dei processi e nella loro predittività.
Condizione necessaria per tali miglioramenti è l’adozione del modello di processo e dei vincoli per disciplinare la loro esecuzione previsti in questo processo visto che i rilievi sono azzerati con questi accorgimenti.
Q3.11 - Quali sono le percentuali di tempo persona richiesti dalle fasi di progetto?
La distribuzione dei tempi-persona consumati nelle fasi di un progetto devono avere un profilo affidabile perché i processi siano prevedibili e quindi monitorabili per rilevare eventuali sprechi o possibilità di miglioramento. Per la diversità di complessità dei progetti, è opportuno che la distribuzione dei tempi-persona consumati in ogni fase sia espressa in percentuale rispetto al tempo- persona totale richiesto da ogni progetto.
La misura da rilevare è:
TFi = Tempo- persona speso per la fase i.ma
Gli indicatori calcolati dalle misure rilevate sono:
TT = tempo-persona totale speso per il progetto in esame
TPi= TFi/TT*100 tempo persona speso per la fase i.ma, in percentuale
Il campo sperimentale deve essere un insieme di progetti che seguono lo stesso modello di processo.
Ciò che si vuole indagare è se il modello di processo definito e i vincoli imposti al TFS per supportare la esecuzione disciplinata del processo migliorano la prevedibilità.
L’insieme di controllo e quello di sperimentazione sono costituiti come per gli altri due quesiti.
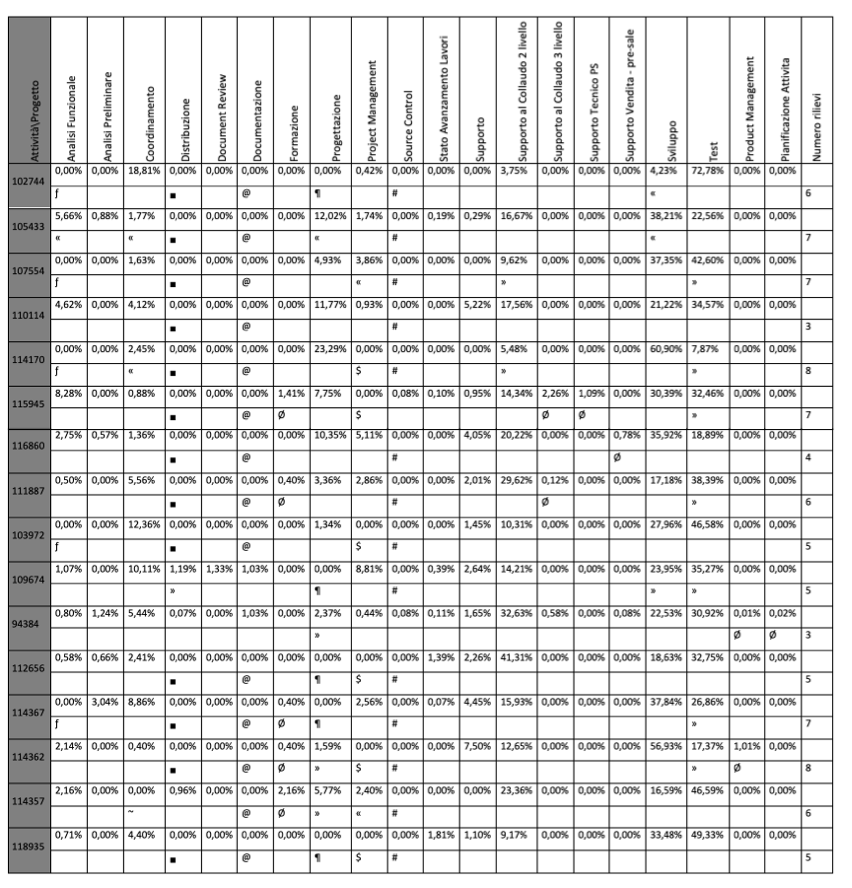
I tempi rilevati per l’insieme di controllo sono mostrati in figura 3.34. Nella stessa figura, come già anticipato, sono mostrati i rilievi dettagliati per fasi.
Per la leggibilità della figura viene riportata di seguito la tabella contente le i simboli che esprimono i tipi di rilievi:
~ - Coordinamento
■ - Distribuzione
@ - Documentazione
$ - Project Management
ƒ - Analisi
¶ - Progettazione
# - Source Control
° - Test non presente
Ø - Attività non prevista
«- Attività eseguita in ritardo
» - Attività eseguita in anticipo
In figura 3.35 sono riportate le box plot della distribuzione di valori di TPi. Da qui si evince che il valore di TP in ogni attività risulta essere molto distribuito, quindi il profilo di distribuzione dei tempi per fase, in ogni progetto, non è definibile entro una fascia ragionevole di oscillazioni. In conclusione risulta carente la prevedibilità dei processi.
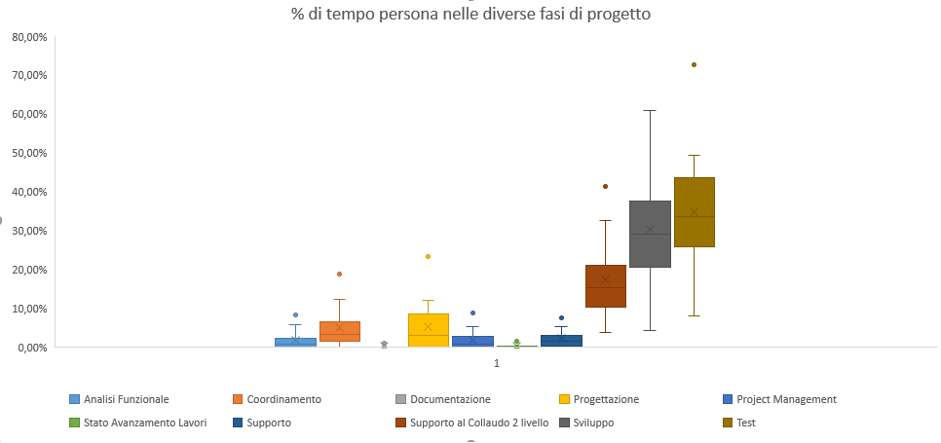
Figura 3.35. Distribuzione dei valori di TPi nella serie di controllo
I tempi rilevati per l’insieme dei 4 progetti sperimentali sono riportati in figura 3.36. Nella stessa figura, come già anticipato, sono mostrati i rilievi dettagliati per fasi che in questo caso sono sempre vuoti perché non ci sono rilievi.

Figura 3.36. Dati progetti TFS per la serie sperimentale
In figura 3.37 sono riportate le box plot della distribuzione di valori di TPi. per la serie sperimentale. Da qui si evince che il valore di TP in ogni attività risulta essere meno disperso, quindi i processi così controllati sono più prevedibili.
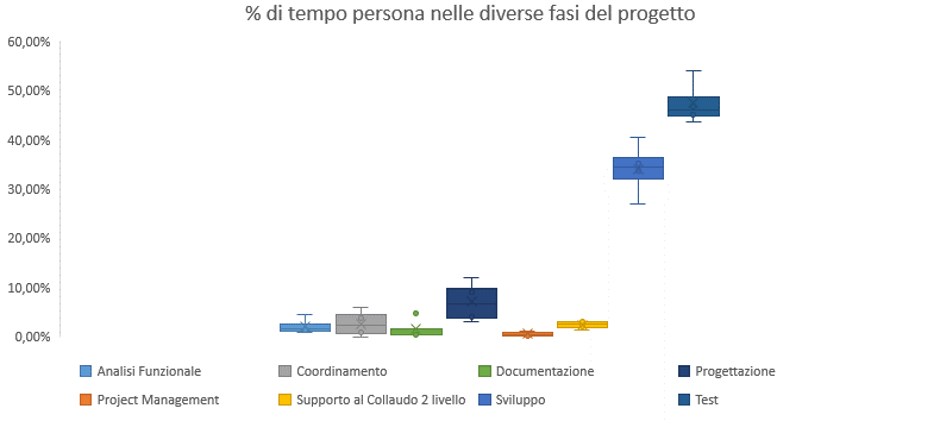
Figura 3.37. Distribuzione dei valori di TPi nella serie sperimentale
In conclusione, i modelli di processo formalizzati ed i vincoli sul TFS per supportare la loro esecuzione conforme consentono di diminuire notevolmente sino all’azzeramento delle non conformità e di migliorare notevolmente la prevedibilità degli stessi. Le conseguenze derivate sono il miglioramento della qualità dei processi, condizione necessaria per il miglioramento della qualità dei prodotti e della individuazione tempestiva degli sprechi, e maggiore prevedibilità della esecuzione dei progetti che usano tali processi.
Qualità dei progetti
La qualità dei progetti è centrale per l’obiettivo olistico di AURIGA 2020 perché i progetti sono la fonte più rilevante di consumo di risorse e di soddisfacimento delle richieste degli utilizzatori. Pertanto, la qualità dei progetti deve essere: monitorata continuamente per assicurare che il suo trend sia coerente con le strategie dell’impresa, ovvero assicurare che essa sia sincronizzata con i cambiamenti del contesto, degli ambienti produttivi e delle caratteristiche dei mercati di destinazione per assicurarsi che gli interventi effettuati per modificare il contesto, le modifiche apportate o subite delle tecnologie utilizzate nella produzione e nell’esercizio del software, i cambiamenti dei requisiti degli utilizzatori non facciano decadere la qualità dei progetti e che anzi la facciano migliorare continuamente a seguito di iniziative appositamente previste; valutata sotto i diversi aspetti di cui si compone e che sono dipendenti tra loro, quindi solo analizzandoli insieme si può avere una visione olistica della qualità; basata sulla esperienza storica accumulata in Auriga e elicitabile dalla letteratura per mantenere e, se pianificato, migliorare il posizionamento competitivo dell’impresa.
Dalle considerazioni precedenti è evidente che per valutare la qualità del progetto sarà necessario un modello di qualità che abbia due essenziali caratteristiche:
Sistematicità: le misure rilevate su ogni progetto devono essere le stesse, devono avere una interpretazione indipendente dal valutatore ma solo dai valori assunti dalle misure e deve suggerire iniziative di miglioramento che devono dipendere solo dalle interpretazioni; pertanto anch’esse indipendenti dal valutatore;
Resilienza: il/i modello/modelli devono adeguarsi facilmente ai cambiamenti del contesto produttivo e di mercato e degli ambienti in cui è applicato garantendo la trasferibilità di conoscenza dagli usi precedenti e migliorarla per gli usi successivi.
Il paradigma per la creazione dei modelli di qualità necessari che si è inteso utilizzare è il Goal-Question-Metrics (GQM) ampiamente descritto in TR3.3, supportato anche dal TR3.2 per quanto attiene alle misure da utilizzare. Il paradigma consente di progettare il modello di qualità come l’insieme del modello metrico e del modello di analisi.
Il modello metrico struttura i goal con i quesiti e relative misure (di base, o indicatori calcolati);
Il modello di analisi definisce un insieme di regole definite con la combinazione degli insiemi di equivalenza, definiti dal progetto del modello di qualità sul dominio di definizione di ogni misura, relativi alle misure in corrispondenza delle quali si definiscono le interpretazioni e le azioni suggerite per il miglioramento della qualità dell’oggetto osservato, nel nostro caso l’oggetto osservato è il progetto.
Il campo sperimentale è dato da 4 progetti in ambienti diversi su cui sono stati applicati a più riprese lo stesso modello di qualità. Per completezza gli Allegati- “Modello Metrico”, “Modello di Analisi” descrivono il modello di qualità in ultima versione. L’applicazione del GQM è stato eseguito in sequenza ai 4 progetti per verificare che la conoscenza accumulata dal modello nei precedenti usi sia applicabile successivamente anche se si sono modificate le condizioni al contorno.
Per verificare se il paradigma adottato ha le caratteristiche enunciate e queste supportano efficacemente l’obiettivo olistico di AURIGA 2020 si è indagato sui seguenti quesiti.
Q3.12 - L’efficacia del modello di qualità migliora con il suo uso?
In questo caso la valutazione è qualitativa.
È stato applicato lo stesso modello più volte su ognuno dei progetti durante la loro esecuzione. Inoltre il modello è stato applicato ai quattro progetti sperimentali cronologicamente.
Per verificare l’efficacia delle iniziative suggerite dal modello di analisi si è operato secondo il processo che chiameremo di “miglioramento continuo” come segue:
- Rilevate le misure, il modello di analisi produce le interpretazioni dello stato dell’aspetto del progetto osservato e suggerisce la/le azione/azioni che si possono adottare per migliorarlo;
- Si decide quali azione realizzare prioritariamente, nel caso che il suggerimento comprenda più azioni in alternativa, e si realizza la corrispondente iniziativa di miglioramento anche durante lo svolgimento in corso del progetto;
- Si ritorna a rilevare le misure che si interpretano secondo lo stesso modello per verificare che il miglioramento previsto sia stato realizzato:
- Se si, il risultato è stato raggiunto, si ritorna al punto “a” per il resto del progetto
- Se no, si analizza se l’iniziativa adottata è corretta
- In caso positivo si ritorna al punto “a” per il resto del progetto.
- In caso negativo si sospende l’iniziativa, si modifica il modello di analisi con i relativi suggerimenti e si ritorna al punto “a” per il resto del progetto.
Quando il progetto in osservazione finisce, il modello di qualità così come risultato dopo le eventuali modifiche è adottato dai successivi progetti.
Una prima osservazione rilevante è che per diminuire il rischio di decisone è bene che i suggerimenti non contengano più iniziative in alternativa. Questo comporta che le regole del modello di analisi debbano essere molto specifiche e ciò è dipendentemente dalle misure. Quindi maggiore è il dettaglio dell’oggetto (processo o prodotto o risorsa) osservato più risulta specifica l’interpretazione e il collegato suggerimento di miglioramento.
Dai contenuti dell’allegato Modello di Analisi si evince che nel nostro caso ci sono diversi suggerimenti che non sono univoci, ovvero prevedono più iniziative che potrebbero essere in alternativa o in una qualche combinazione tra loro. Per poter migliorare questa situazione sarebbe opportuno affinare le regole che, a sua volta, richiede una più affinata misurazione ovvero maggiore dettaglio nella definizione del processo sottostante i progetti. Questo riporta agli standard di processo di cui si è discusso prima. Pertanto per migliorare la progettazione dei modelli utilizzati è necessario migliorare lo standard dei processi utilizzati. Quest’ultimo obiettivo non è stato possibile realizzarlo entro i tempi disponibili in questo PIA, quindi anche il miglioramento del modello è sospeso e rimandato alla industrializzazione dei risultati del presente progetto.
Una volta avviata un’iniziativa di miglioramento è opportuno che questa sia il più presto possibile interrotta se non raggiunge il miglioramento desiderato, così che gli sprechi siano ridotti; oppure, sia il più presto possibile disseminata ad altri progetti in corso in parallelo a quello in corso se questa raggiunge i risultati desiderati. Per raggiungere questo risultato è necessario che l’analisi dello stato di qualità del progetto sia il più rapido possibile e questo dipende dalla estensione del “dominio di sincronizzazione” del modello di qualità.
Il dominio di sincronizzazione è l’intervallo di tempo in cui tutte le misure previste in un modello sono rilevabili. Per esempio: se una misura del modello ha rilevazione settimanale e tutte le altre hanno rilevazione giornaliera, il dominio di sincronismo è settimanale, l’analisi delle misure si può fare, al più presto, ogni settimana e si perde l’informazione su quanto sia accaduto nei giorni della settimana in cui non si è potuta fare l’analisi a quelli aspetti che sono operazionalizzati dalle misure rilevate a cadenza giornaliera. Per completezza, se si eseguisse l’analisi in un giorno infrasettimanale il modello di analisi non troverebbe il valore della misura a frequenza settimanale, quindi alcune regole previste da esso non sarebbero valutabili e di conseguenza non sarebbe in grado né di interpretare ciò che sta accadendo né di produrre suggerimenti.
Nella progettazione dei modelli di qualità si deve curare che le misure previste abbiano il periodo di rilevazione il più omogeneo possibile per rendere il più piccolo possibile il dominio di sincronizzazione.
Purtroppo però un progetto si estende su periodo di tempi anche molto lunghi e quindi diventa impossibile rispettare esattamente questa condizione. Per esempio se si deve osservare lo sviluppo ed il test può accadere che mentre il test di sistema è eseguito subito dopo la fine dello sviluppo, mentre il test di accettazione, essendo dipendente dalla disponibilità dell’utilizzatore, potrebbe slittare nel tempo di un periodo che non può essere previsto quando si schedula il progetto e, men che meno, può essere previsto quando si progetta il modello di qualità. Allora la asserzione precedente conviene modificarla come segue: nella progettazione dei modelli di qualità si deve curare che le misure previste abbiano il periodo di rilevazione il più omogeneo possibile per rendere il più piccolo possibile il dominio di sincronizzazione; almeno deve essere omogeneo per le misure incluse in ogni quesito previsto nel modello di qualità.
Progettando il modello di qualità in questo modo si può estrarre periodicamente il rapporto di analisi avendo il/i quesito/quesiti fuori sincronia con gli altri quesiti, senza analisi (allegato “Monitoraggio Progetti con Analisi Incompleta”). Questo darebbe comunque la possibilità di monitorare il progetto incrementalmente.
Per completezza, i quesiti su aspetti che si possono considerare quasi invarianti per tutto il progetto avranno misure i cui valori saranno validi in ogni rilevazione effettuata, ad esempio nella nostra indagine il quesito “Quale è l’ambiente progettuale” (cfr. allegato- “Modello Metrico”) è un quesito che si può considerare invariante durante tutto il progetto perché si suppone che l’assegnazione delle risorse al progetto non vari per l’intero progetto. Nonostante ciò per la resilienza del modello quando dovesse cambiare l’ambiente nel progetto le misure di questo quesito sarebbero rilevabili in ogni tempo quindi si adeguerebbero al dominio di sincronizzazione degli altri quesiti. Inoltre, il rapporto di analisi rivelerebbe come il cambiamento dell’ambiente progettuale ha sulla qualità (cfr. allegati “Monitoraggio prima e dopo la variazione dell’ambiente”).
Il dominio di sincronizzazione deve essere il più piccolo possibile. Così che le iniziative messe in campo dall’osservazione di un progetto, in questo caso, di un oggetto in generale, possano essere verificate nella loro efficacia più tempestivamente. Questo assicura la minimizzazione degli sprechi nel caso che le iniziative di miglioramento falliscano e la massimizzazione dei vantaggi nel caso contrario.
Più dettagliatamente: se i progetti durano poco tempo, le iniziative suggerite dalla osservazione di un progetto è realizzata in un primo incremento significativo, piuttosto che completamente. La parte realizzata è messa in campo in un prossimo progetto; questo essendo piccolo potrà subito far osservare se l’iniziativa tende a dare i risultati previsti. In caso negativo, l’iniziativa suggerita è sbagliata quindi non conviene realizzare ulteriori incrementi; così che si è speso inutilmente meno di quanto si sarebbe speso se l’iniziativa fosse completamente realizzata. In caso positivo: da un lato si continua a realizzare l’iniziativa, dall’altro lato quella parzialmente realizzata si applica già in altri progetti così che produca i miglioramenti, anche se parziali, tempestivamente. In quest’ultimo caso si stanno realizzando i vantaggi producibili dall’iniziativa, anche se parzialmente, il più presto possibile.
Q3.13 - La conoscenza accumulata nel modello di qualità è trasferibile tra diversi progetti, nonostante siano cambiati gli sviluppatori e le condizioni in cui operano?
Anche per questo quesito la valutazione è qualitativa.
Le misure previste nel modello devono essere tutte rilevabili su ognuno dei progetti. Altrimenti il modello non è in grado di produrre una valutazione omogenea per tutti i progetti.
Gli sviluppatori hanno analizzato le interpretazioni per valutare la loro coerenza con la realtà. Quando queste non erano considerate tali, sono stati modificati i modelli e riverificati con la loro successiva applicazione. dopo ogni modifica, anche quando gli sviluppatori che ne hanno valutato la coerenza sono cambiati la valutazione è sempre migliorata. Questo conferma che la conoscenza espressa nei modelli di qualità si accumula ed è trasferita conformemente tra gli sviluppatori e nel tempo.
Come è stato descritto nel quesito precedente, il modello di qualità elaborato durante l’uso nel monitoraggio di un progetto, migliorato nella sua struttura, è trasferito ai progetti successivi. Pertanto il sistema di modelli di qualità previsto per il monitoraggio dei progetti è un accumulatore di conoscenza che si propaga nel tempo in tutta l’impresa.
Q3.14 - Quali sono i costi di progettazione e gestione dei modelli di qualità?
Il ciclo di vita di un modello di qualità è costituito essenzialmente da:
- Progettazione, produzione del modello metrico e del modello di analisi;
- Evoluzione, modifica del modello metrico e/o del modello di analisi a seguito di una esigenza di miglioramento scaturita dal test del modello di qualità o dal suo uso.
- Raccolta dati, raccolta e controllo di correttezza di tutti i dati richiesti dal goal ed appartenenti ad un intervallo di sincronizzazione; in questi;
- Inserimento dati, inserimento dei dati raccolti nel sistema di automazione del GQM, nel nostro caso AURKEB;
- Esecuzione, esecuzione del modello di qualità in uno o più intervalli di sincronizzazione che hanno tutti i dati necessari immessi correttamente.
I costi di progettazione è opportuno censirli per quesiti piuttosto che per goal, perché goal diversi possono avere un numero di quesiti molto differente tra loro.
Durante i test effettuati su AURKEB con gli stessi modelli riportati dagli allegati sono stati rilevati:
TPQ = Tempo di Progettazione del Quesito: impegno-persona in hh necessario per la progettazione dei modello metrico e modello di analisi corrispondente ad ognuno dei quesiti previsti dai goal.
TEQs = Tempo di Evoluzione Strutturale del Quesito: impegno persona in hh per migliorare la struttura di un quesito modificando il modello metrico e/o il modello di analisi corrispondente ad un quesito.
TEQa = Tempo di Evoluzione per Affinamento del Quesito: impegno persona in hh per migliorare un quesito senza modificare la struttura ma intervenendo solo sulle asserzioni del modello metrico e/o modello di analisi.
I tempi di evoluzione sono stati distinti perché ci si aspetta che siano notevolmente diversi se si considera che se si deve intervenire sulla struttura del quesito il problema è analogo alla progettazione dello stesso anche se si è di fronte ad una struttura già esistente perché quest’ultima si deve ristrutturare.
In figura 3.38 sono mostrati i dati rilevati durante i test che hanno richiesto 4 evoluzioni per arrivare alla configurazione attuale dei goals, riportata negli allegati. Nella tavola i quesiti hanno l’indice diviso in due cifre: la prima indica il numero d’ordine del goal a cui appartiene il quesito; la seconda il numero d’ordine del quesito nel goal
Dalla figura 3.38 si evince che TPQ è molto simile ai TEQs e questi sono molto differenti dai TEQa. Si può anche notare che qualche volta il TEQs è maggiore del corrispondente TPQ, questo significa che la disponibilità di una struttura dei modelli nella reingegnerizzazione potrebbe essere un ritardatore piuttosto che un acceleratore e comunque la reingegnerizzazione dei modelli richiede un impegno-persona molto simile alla progettazione, Ciò è spiegabile con la considerazione che i due modelli, metrico e analitico, sono dipendenti tra loro quindi è alta la probabilità che la modifica di uno comporti quella dell’altro dovendo mantenere coerenti i contenuti dei due modelli.
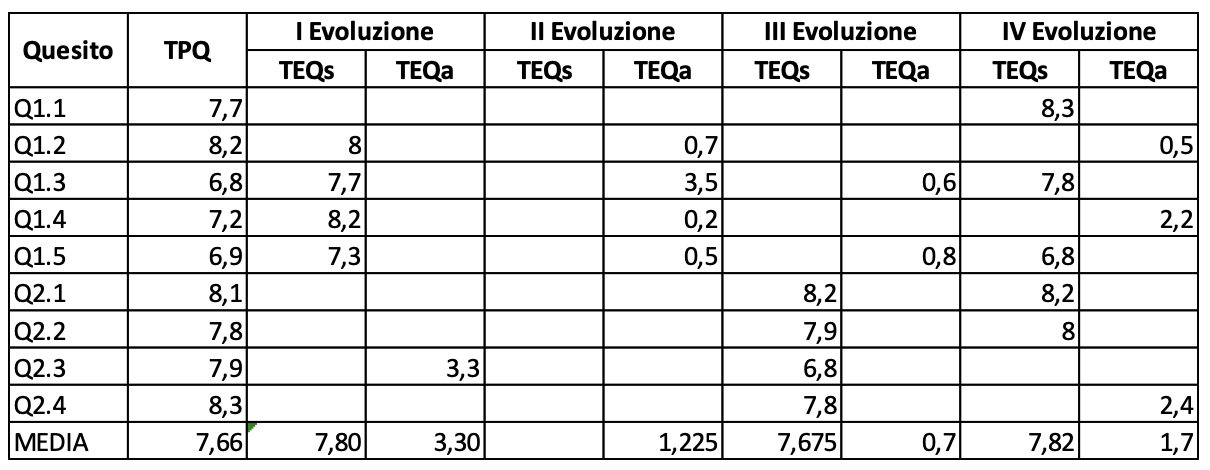
Figura 3.38. Tempi (in hh-persona) di progettazione ed evoluzioni per quattro miglioramenti
In figura 3.39 sono riportate le box plot di TPQ e dei TEQs. Qui si conferma graficamente la similitudine tra la serie dei TPQ e le serie dei TEQs. Inoltre si rileva che la dispersione dei valori nelle serie è relativamente piccola, quindi le medie espresse in figura 3.38 si possono considerare dei buoni valori di riferimento per la previsione del tempo-persona necessario per la progettazione e la evoluzione di un quesito.
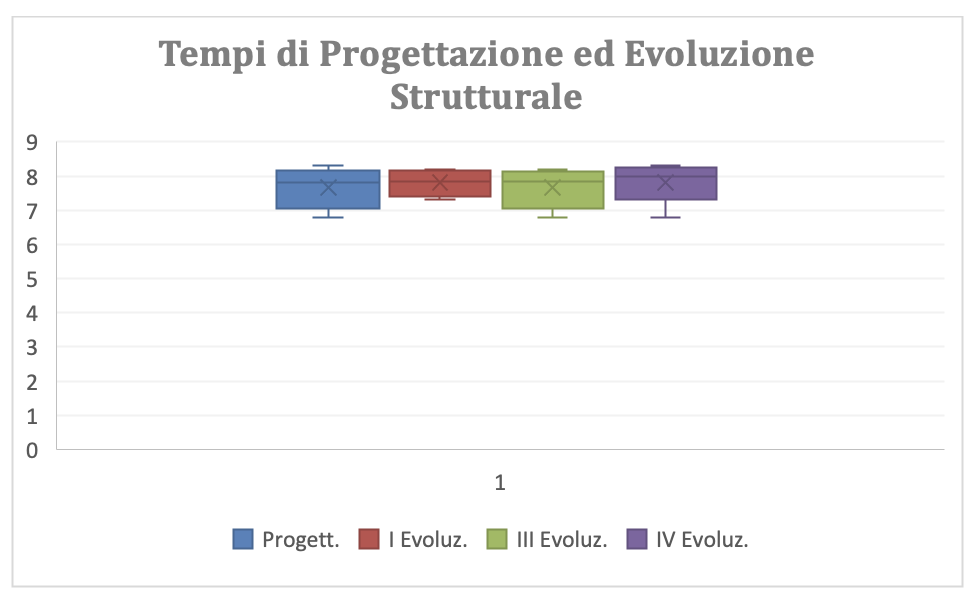
Figura 3.39. Box Plot di TPQ vs TEQs
In figura 3.40 è riportato invece il grafico di dispersione dei valori di TEQa riportati in figura 3.38. Da questa figura si evince che la dispersione dei TEQa è molto elevata e che quindi le medie di questi, molto diverse tra loro, non possono essere considerati dei buoni valori di previsione dell’impegno-persona necessario per l’affinamento di un quesito. Si può dire solo che con buona probabilità l’affinamento richiede un tempo intorno all’ora.
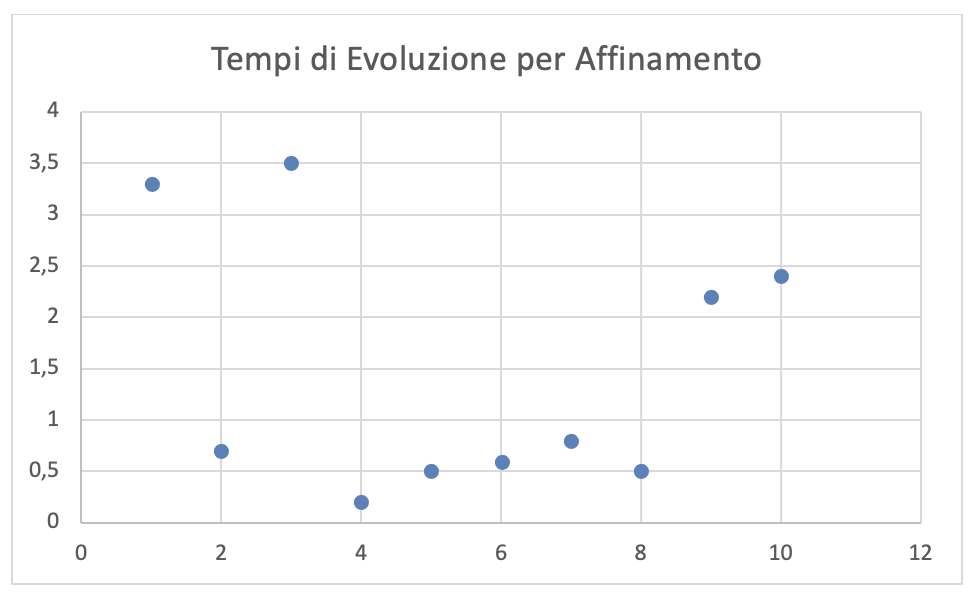
Figura 3.40. Diagramma di dispersione dei TEQa
Per quanto riguarda la raccolta e l’inserimento dati sono stati rilevati:
TR = Tempo per la raccolta dei dati. Tempo-persona (in hh) necessaria per raccogliere i dati previsti nel modello metrico di un goal e per il loro controllo. Nel caso che una misura sia derivata questo tempo è la somma del tempo necessario per raccogliere i dati elementari e quello per calcolare il dato derivato.
TI = Tempo per la Immissione dei dati. Tempo-persona (in hh) per la immissione nel sistema di gestione del GQM dei dati raccolti.
In figura 3.41 sono riportati i tempi rilevati per la raccolta ed immissione delle misure previste nei due goal sperimentati per le quattro applicazioni costituenti il campo sperimentale.
I dati sono stati raccolti in ordine cronologico per le quattro applicazioni che costituiscono il campo sperimentale. Mentre per la prima e la seconda applicazione sono stati raccolti e immessi tutti i dati manualmente. Per la terza e la quarta applicazione sono stati utilizzati gli strumenti che, nel frattempo sono stati approntati, per la raccolta automatica e la immissione della gran parte di dati dalle loro fonti.

Figura 3.41. Tempi (i hh-persona) per la raccolta e la immissione delle misure
Dalla lettura dei dati in figura 3.41 si rileva che la raccolta automatica dei dati riduce notevolmente il tempo-persona della fase di raccolta e di immissione dei dati. La figura3.42.a e la figura3.42.b mostrano graficamente il confronto dei valori, rispettivamente di TR e TI, con la raccolta manuale e automatica delle misure.
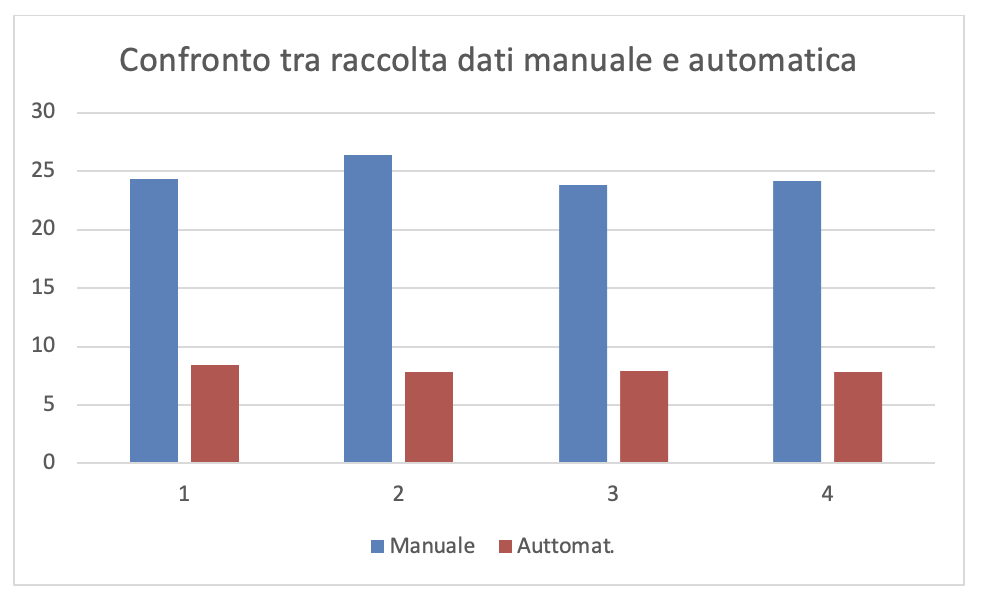
Figura 3.42.a. Visualizzazione grafica del TR nella raccolta manuale vs la raccolta automatica
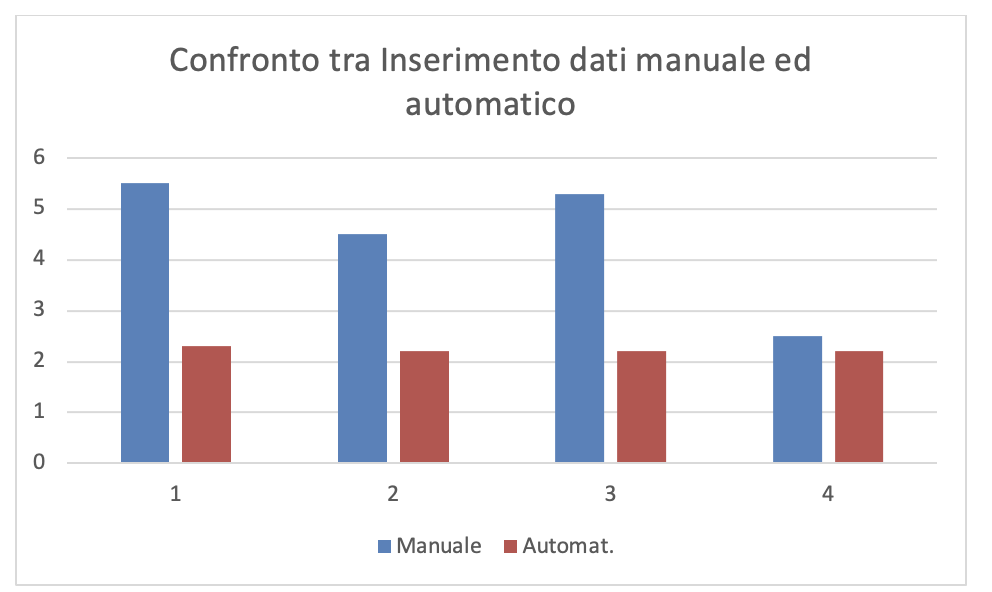
Figura 3.42.a. Visualizzazione grafica del TI nella raccolta manuale vs la raccolta automatica
Non è possibile utilizzare i dati presenti nelle figure precedenti come base per la previsione dei tempi di raccolta delle misure e dei tempi di immissione dei dati perché questi dipendono essenzialmente dalle fonti e da quanto la fornitura dei dati sia conforme alla modalità con cui devono essere immessi nel sistema di gestione del GQM.
Ciò che si può concludere è che nella progettazione del GQM è necessario prevedere le misure più significative per gli aspetti che si vogliono osservare: non conviene utilizzare misure che generano poca o nessuna discriminazione nel modello di analisi; in ogni caso, il progettista del modello di qualità si deve sforzare di utilizzare le misure che si recuperano automaticamente e che possano essere immesse nello strumento di gestione del GQM altrettanto automaticamente.
I tempi di esecuzione sono trascurabili perché lo strumento di gestione del GQM, nel nostro caso AURKEB, esegue qualunque modello in automatico e produce il rapporto di analisi relativo in tempi dell’ordine di pochi secondi.