Naviga tra le sottosezioni
Molti dei pacchetti software nell’offerta di Auriga hanno evoluzioni frequenti. Pertanto è necessario eseguire frequentemente sia test di sistema sia test di accettazione. Altresì, ogni volta che si fanno modifiche è necessario assicurarsi che non ci siano state regressioni. Perciò è necessario accumulare casi di test che possano garantire la validazione del comportamento di ogni componente del software e costituire un corrispondente oracolo che raccolga le risposte che la componente testata deve dare ad ogni caso di test. È evidente che con il tempo sia il patrimonio di casi di test sia il corrispondente oracolo aumenta in dimensioni.
Per quanto detto, per far diminuire i costi e aumentare la qualità è necessario che la raccolta del patrimonio di casi di test ed il corrispondente oracolo debba essere automatico, il più possibile. Altresì, deve essere automatico anche la esecuzione dei casi di test per la regressione e la valutazione del risultato del test attraverso l’oracolo.
A tale scopo in Auriga sono necessari due tipi di strumenti per test automatici:
- Quello che prevede la virtualizzazione delle macchine ATM e CSA, poiché molti dei sistemi software venduti da Auriga hanno lo scopo di gestire queste macchine e sono in esercizio sulle stesse, quindi il loro test richiede il loro uso da ognuna delle macchine per cui lo steso software si dichiara compatibile. Se non si avesse la virtualizzazione di tali macchine si dovrebbero avere tutti gli esemplari nel laboratorio di prova del software. Inoltre se non si avesse lo strumento per la esecuzione dei test automatici, lo stesso piano di test dovrebbe essere eseguito su ognuna delle macchine per cui il software è dichiarato compatibile. È immediata la considerazione che uno strumento automatico che virtualizzi tali macchine ha grandi prospettive di generare economie: risparmia l’uso delle macchine, lo spazio per la presenza delle macchine in laboratorio, i tempi di esecuzione del test.
- Quello che esegue i casi di test in patrimonio per applicazioni WEB. Questo tool serve per la validazione dei software che sono in funzione sui server e che acquisiscono i dati da elaborare dai sistemi che gestiscono le macchine, di cui al punto precedente. Questo strumento non ha bisogno della virtualizzazione, ma solo della capacità di raccogliere e gestire il patrimonio di casi di test per validare le componenti dei sistemi funzionanti e di eseguirli automaticamente. Il risparmio generato da questo tipo di strumento sta nella diminuzione dei tempi di esecuzione dei test.
Per quanto detto, in questo capitolo si descrivono le indagini effettuate per i due tipi di strumenti enunciati
TEST DI SISTEMA CON VIRTUALIZZAZIONE ATM/CSA
Q4.1 - Qual è l’affidabilità di FIS?
Ciò che si desidera è che FIS quando usa in piano di test di regressione i casi di test a patrimonio per lo stesso prodotto, provenienti da test di sistema precedenti, non generi falsi positivi. Infatti, questi ultimi richiederebbero tempo-persona per analizzare le cause dei risultati positivi. Tale tempo sarebbe sprecato perché avrà come risultato che non esiste alcun difetto nel software che abbia generato il risultato positivo.
Per verificare questo aspetto, si sono eseguite su versioni diverse dello stesso software uno stesso set di casi di test estratti dal test di regressioni, per verificare che l’oracolo sia sempre valido, indipendentemente dalle condizioni in cui il software opera.
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato. Per falso positivo qui si intende un risultato positivo generato dalle condizioni in cui il software ha operato e non dal fatto che ci siano difetti nello stesso software.
NET: insieme di casi di test estratti dal patrimonio comune come test di regressione, compresi nel piano di test.
Si calcola
TFP: tasso di falsi positivi = NFP/NT*100. Questo serve a normalizzare il risultato e poter paragonare piani di test di dimensioni diverse.
Sono stati eseguiti 8 casi di studio. I risultati sono riportati in figura 4.1. la media dei falsi positivi è pari a 5,37. La distribuzione dei risultati è riportata in figura 4.2 da cui si evince che questi sono poco distribuiti, quindi la media può essere considerata un buon indicatore del fallimento che il tool può provocare a causa delle condizioni in cui opera.

Figura 4.1. Risultati circa l’affidabilità di FIS.
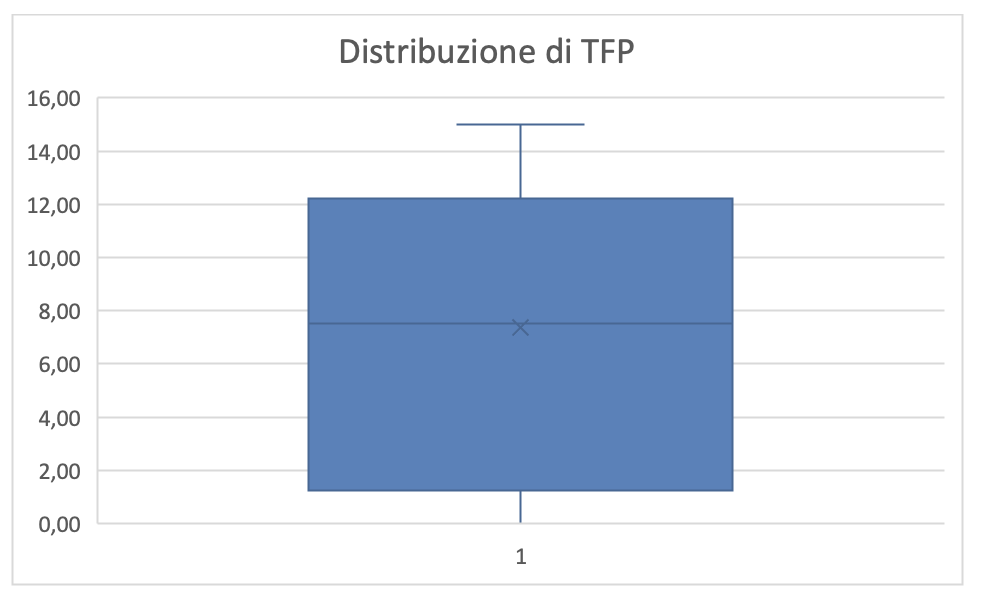
Figura 4.2 Box Plot dei risultati
L’uso di FIS è soddisfacentemente affidabile, rispetto agli obiettivi di economicità che si prefigge, ma ci sono margini di miglioramento che potranno essere acquisiti migliorando incrementalmente la programmazione della esecuzione dei casi di test. Ovvero l’oracolo di FIS è un accumulatore di conoscenza dei tester espressa nella programmazione di esecuzione dei casi di test.
Q4.2 - Qual è la stabilità di FIS?
Un altro aspetto utile è che per lo stesso prodotto e per lo stesso patrimonio di casi di test con il relativo oracolo, quando si esegue il test di regressione in ambienti diversi non si verifichino falsi positivi.
Per verificare questa caratteristica sulle stesse versioni di software si esegue lo stesso piano di test più volte ma in condizioni diverse rilevando le seguenti misure per ogni versione e per ogni riesecuzione:
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato.
NET: insieme di casi di test estratti dal patrimonio comune, compresi nel piano di test.
AMB: descrizione dell’ambiente di prova
Si calcola
TFP: tasso di falsi positivi = NFP/NT*100.
Il prodotto considerato in ogni prova è sempre lo stesso. Le prove, si differenziano per le condizioni in cui gli stessi casi di test sono eseguiti. Le condizioni sono cambiate perché sono diversi i tempi di esecuzione. Ogni volta che si esegue uno stesso caso di test è verificata la validità dell’oracolo.
I risultati sono riportati in figura 3. La medi di FTP in questo caso è di 3,67. La dispersione dei risultati è mostrata in figura 4 che mostra come questa sia soddisfacente anche se soggetta a miglioramenti.

Figura 4.3. Risultati circa la stabilità di FIS

Figura 4.4. Distribuzione dei dati circa la stabilità di FIS
L’uso di FIS è soddisfacentemente stabile, rispetto agli obiettivi di economicità che si prefigge, ma ci sono margini di miglioramento che potranno essere acquisiti migliorando incrementalmente la programmazione della esecuzione dei casi di test. Si conferma che l’oracolo di FIS è un accumulatore di conoscenza dei tester espressa nella programmazione di esecuzione dei casi di test.
Q4.3 - Qual è la flessibilità di FIS?
Il patrimonio di casi di test aumenta nel tempo. Pertanto è necessario che quando si pianifica il test di regressione sia opportuno che si selezionino dal patrimonio solo i casi di test necessari per la particolare regressione. Diversamente si sarebbe costretti ad eseguire tutti i casi di test in patrimonio, questo aumenterebbe la probabilità di falsi positivi e, quindi, il tempo-persona sprecato per analizzare questi, com’è stato rilevato nei quesiti precedenti.
Il tool di esecuzione automatica dei test dovrebbe dare la possibilità di selezionare i casi di test attraverso dei parametri di selezione. È opportuno verificare se tali parametri di selezione riescano a prevedere i casi reali in cui si troverà il progettista del test così che con essi riesca a estrarre tutti i casi di test che servono per la regressione che deve essere provata. Questo ci assicura che il tool è flessibile rispetto a tutte le situazioni di selezione necessarie all’interno del patrimonio di test che, si consideri, sarà incrementalmente sempre più numeroso.
Per verificare questa caratteristica su differenti software o su differenti versioni dello stesso software le misure da rilevare sono:
CTA: numero di casi di test attesi nella selezione per il test di regressione sul prodotto testato.
CTS: numero di casi di test estratti nella selezione per il test di regressione per ogni prova sul prodotto.
CTD: numero di casi di test che differenziano i due insiemi precedenti= numero di casi di test attesi e non estratti+ numero di casi di test estratti ma non utili
Si calcola
TTD: tasso della differenza dei casi di test= CTD/CTA*100
Purtroppo, Il prodotto FIS e la sua estensione “Regression Test Manager” che permette di registrare, modificare ed eseguire i test automatici, non permette in alcun modo di eseguire automaticamente una selezione di casi di test in base a dei criteri dati.
La selezione dei casi di test deve venire effettuata manualmente, sebbene esista un sistema di “TAG” che opportunamente associati ai casi di test in fase di progettazione permette di ricercare specifici casi di test.
Per eseguire dei casi di test essi devono essere inseriti in dei Test Set, ogni Test Set può contenere un qualsivoglia numero di casi di test, al momento per permettere un’esecuzione corretta dei casi di test i criteri discriminanti utilizzati, in fase di progettazione, per inserire un determinato caso di test all’interno di un Test Set sono i seguenti:
Il cliente e la versione installati sulla macchina
Il modello di macchina virtuale (Es. Diebold868, è il modello su cui quel test set va eseguito)
La carta utilizzata (dev’essere la stessa per tutti i casi di test di cui il test set è composto)
La funzionalità che viene testata dal Test Set
È quindi possibile, grazie ad una corretta progettazione dei Test Set, selezionare solamente i casi di test relativi alle funzionalità interessate dalle modifiche apportate dalla release di WWS in questione. Tuttavia questa operazione rimane totalmente manuale.
A causa di questa mancanza al momento invece di eseguire un’operazione di selezione dei casi di test, preliminare all’esecuzione stessa dei test automatici. Vengono direttamente eseguiti tutti i casi di test già registrati presenti nel patrimonio del cliente in questione.
Q4.4 - Qual è la sistematicità di FIS?
L’uso di FIS consente ai tester di gestire il patrimonio dei casi di test ed in corrispondenza gestire l’oracolo sistematicamente; ovvero, i contenuti delle due tecnologie risultano corretti indipendentemente dal tempo in cui sono stati prodotti e dal Tester che li ha prodotti.
Per verificare questa caratteristica, è stata eseguita un’indagine in cui 2 tester diversi hanno scritto lo stesso piano di test, utilizzando lo stesso patrimonio di casi di test per 13 casi di studio; ogni caso di studio è una nuova funzione della stessa applicazione. Per ogni prova (piano di test sullo stesso software da due tester diversi) sono state prelevate le seguenti misure:
NCT: numero di casi di test del piano eseguito per ogni prova sul prodotto testato.
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato.
DFP: numero di falsi positivi differenti rilevati dai due tester
Si calcola
TDFP: tasso delle differenze dei falsi positivi = DFP/NCT*100
In Figura 4.5 sono riportati i risultati. Il tasso della differenza tra i falsi positivi è ragionevolmente piccolo. A rinforzo di questa affermazione è opportuno notare che: il numero complessivo degli NFP sono quasi uguali per i due soggetti sperimentali; la distribuzione degli errori è 6 volte a vantaggio del tester 1, 4 a vantaggio del tester 2 e 3 volte paritario. In conclusione i due soggetti sperimentali hanno la stessa abilità ad utilizzare le tecniche di programmazione dell’esecuzione dei casi di test. Pertanto le tecniche di programmazione disponibili attualmente e la loro disseminazione sono soddisfacenti.
La media di TDFP sarebbe opportuno che fosse più piccola ma questa dipende dal miglioramento dell’affidabilità di FIS. In figura 4.6 è mostrata la box plot della dispersione di TDFP da dove si vede che questa è relativamente piccola quindi la media può essere considerata un buon indicatore della sistematicità. Con il miglioramento dell’affidabilità di FIS diminuirà anche questo indicatore, ovvero diminuirà il rischio che il piano di test eseguito con FIS possa dare risultati diversi dipendentemente dal tester che lo ha programmato.

Figura 4.5. Dati circa la sistematicità di FIS
Figura 4.2 Box Plot dei risultati
Con il miglioramento della programmazione dei casi di test l’oracolo corrispondente al patrimonio di casi di test sarà sempre più affidabile. Quindi si rinforza l’asserzione secondo cui FIS è un agente di accumulo di conoscenza patrimonializzata.
Q4.5 - Qual è la trasferibilità di FIS?
La conoscenza accumulata in FIS, i metodi e le tecniche definite per la programmazione dei casi di test devono essere facilmente trasferibili per costituire economicamente e tempestivamente competenze specializzate di tester per programmi che funzionano su ATM e CSA.
Per provare questo aspetto sono state utilizzate due coorti a cui sono stati erogati corsi su FIS con modalità FLIPPED CLASSROOM (dettagliata nel capitolo 8 di questo TR). Le misure rilevate sono state:
TF: tempo in hh speso per la formazione dei Tester all’uso di FIS per la coorte Ima.
TA: Tempo in hh speso per addestrare i Tester all’uso di FIS per la coorte Ima. {quesiti}: quesiti sollevati dai tester sia durante il corso sia durante le operazioni sperimentali, per la classe Ima di tester.
In TF e TA è considerata la somma dei tempi spesi in ogni edizione del corrispondente corso.
In Figura 4.7sono riportati i risultati rilevati.

Figura 4.7. Dati sulla trasferibilità
Queste misure servono a prevedere il costo per la costituzione delle competenze specialistiche sul FIS. Dalla tavola si vede che è migliorabile il TA, ma il suo miglioramento è dipendente dal miglioramento della parte concettuale. Ridurre il TA è molto importante per la economicità e la tempestività della formazione perché questa parte dura di più ed è la più costosa per ogni ora perché è quella che prevede la presenza continuativa di almeno un tutor e la presenza sincrona, in laboratorio, di tutti i discenti.
Nelle figure 4.8.a, 4.8.b, 4.8.c sono riportati i quesiti posti dai discenti

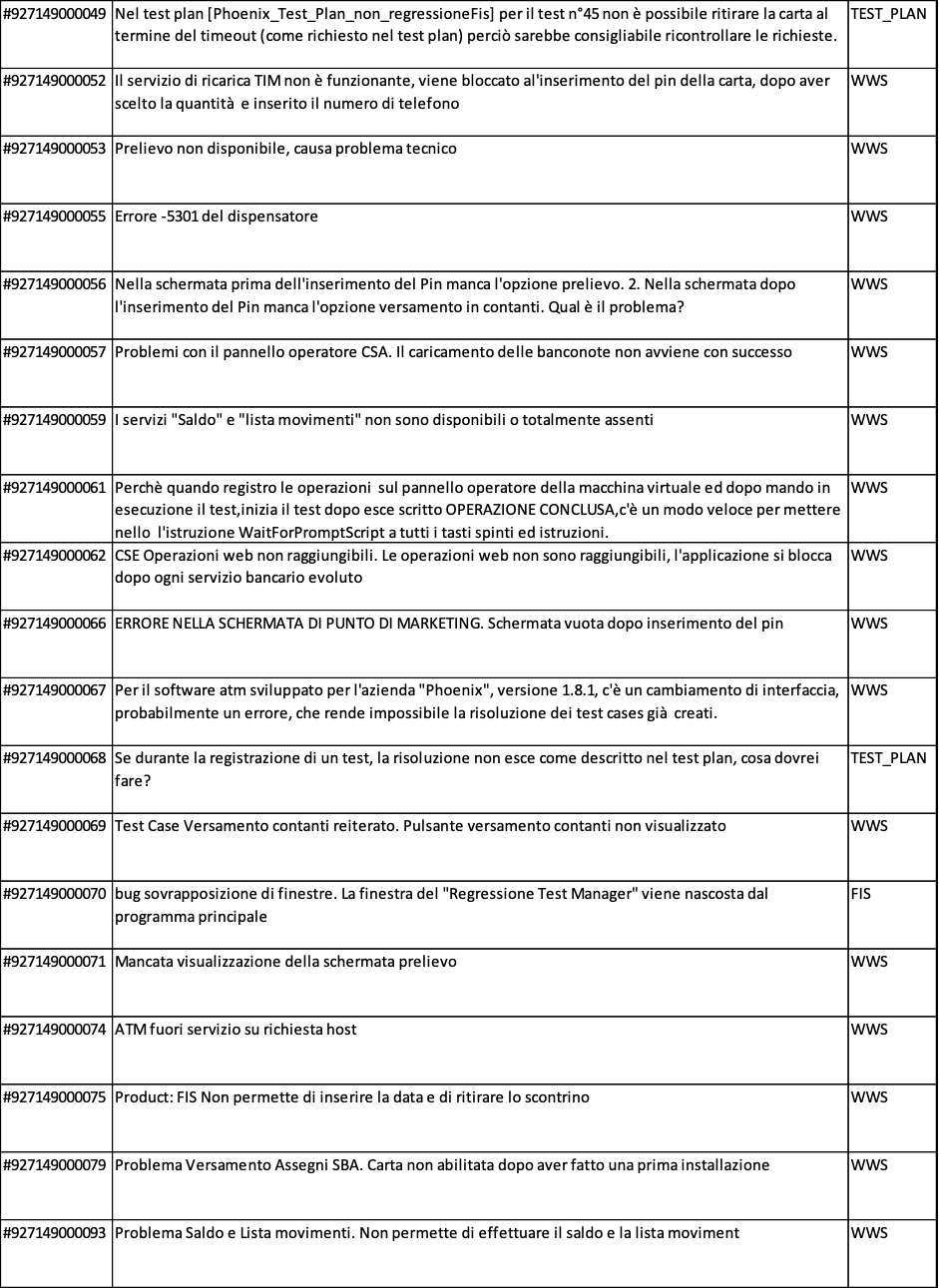
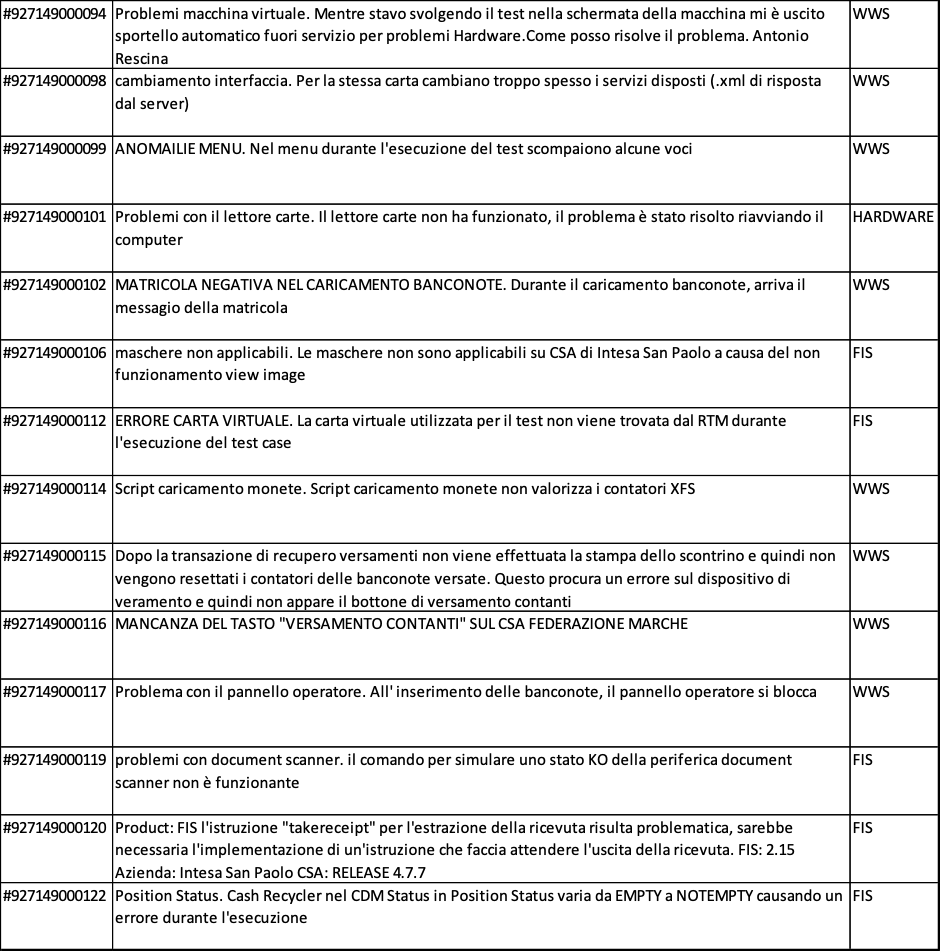
Perciò è opportuno analizzare i quesiti che i discenti hanno posto al docente ed al tutor per comprendere come migliorare i contenuti dell’e-learning. In figura 4.9.a è mostrata una statistica sintetica dei quesiti pervenuti. In figura 4.9.b è mostrato il grafico dei dati statistici. Si evince che per supportare meglio i discenti è necessario migliorare nell’attuale corso la descrizione del WWS, che è il prodotto oggetto sia dei casi di test che si devono produrre sia di quelli che si trovano nel patrimonio comune. Inoltre è opportuno migliorare anche la descrizione di FIS. In conclusione il corso e-learning e il caso di studio che costituiscono la base della formazione dei tester sono anch’essi veicolo di patrimonializzazione di conoscenza e facilitatori di trasferimento della stessa conoscenza.

Figura 4.9.a. Statistiche dei quesiti
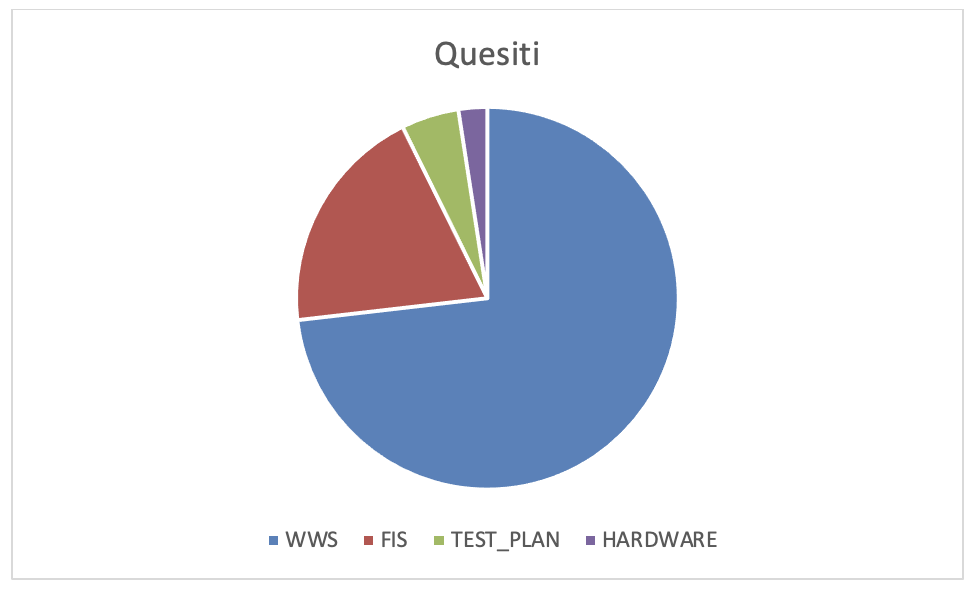
Figura 4.9.b Grafico delle statistiche
È giusto il caso di evidenziare che la formazione è stata efficace, tanto da dare i risultati mostrati nei quesiti precedenti.
Q4.6 - Qual è l’efficienza dei tester supportati da FIS?
Per valutare i costi che comporta la produzione di un piano di test con il FIS è opportuno indagare quale sia la efficienza dei tester supportati da questo tool risultante da alcuni casi di studio appositamente progettati.
Sono stati indagati 9 casi di studio. Per quattro di questi casi di studio sono stati prodotti due piani di test in sequenza cronologica, per gli altri ne è stato progettato uno per ognuno e quello considerato è il primo caso di test registrato in FIS per la corrispondente applicazione. Ogni caso di studio è assegnato ad un diverso soggetto sperimentale.
Le misure rilevate per ogni caso di studio sono, per ogni piano di test prodotto:
ET: effort in hh-persona speso dal tester per il piano di test sperimentale; in questo è compreso sia la selezione dei casi di test dal patrimonio comune sia la scrittura di nuovi test e la produzione del relativo oracolo
NCT New: numero di nuovi casi di test inseriti nel piano di test
NCT: numero di casi di test totali nello stesso piano di test
Si calcola
E: efficienza = NCT/ET (casi di test per hh-persona) nella produzione di un piano di test contenente NCT casi di test.
L’effort è misurato dall’ora di inizio schedulata per l’assegnazione della prova ad un tester fino all’ora di fine della prova, senza considerare il tempo speso dallo strumento per eseguire automaticamente il test di regressione. Il momento della fine della prova è quello in cui il tester consegna su TFS il risultato previsto dalla prova. Il tempo speso da FIS si rileva dallo stesso FIS, questo deve essere sottratto al tempo che intercorre dall’inizio alla fine della prova, come risulta da TFS per poter ricavare esattamente l’effort speso dal tester.
Le liste dei casi di test da cui ricavare NCTNew e NCT saranno rilevate da quelle depositate in TFS dal tester che ha eseguito la prova.
In figura 4.10 sono mostrati i dati rilevati nell’indagine.

Figura 4.10. Dati inerenti l’efficienza per FIS
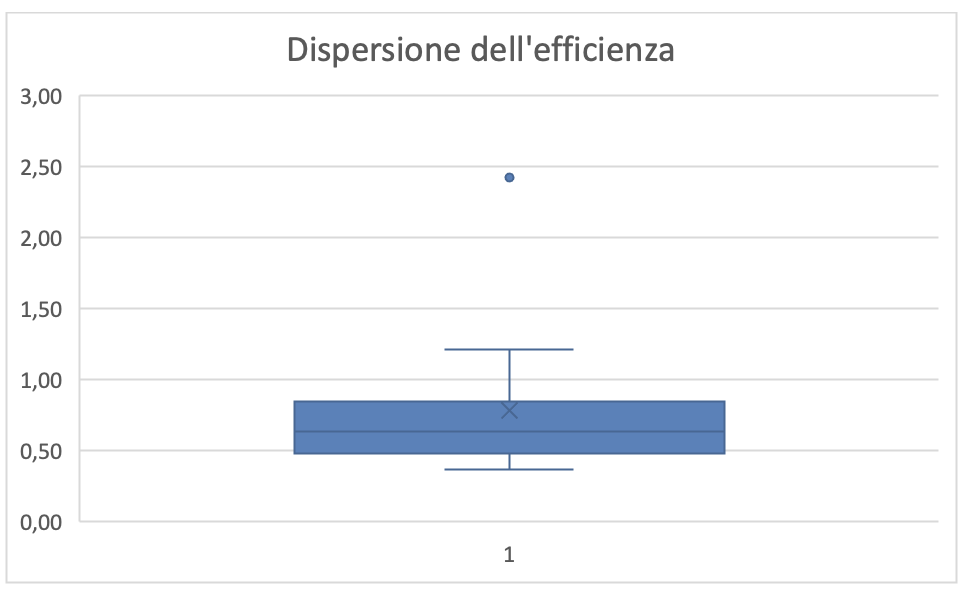
Figura 4.11 Dispersione di E per FIS
Dalla figura 4.10 si evince che il patrimonio di casi di test che si accumula in FIS assicura che la efficienza nella produzione del piano di test aumenta incrementalmente con le successive evoluzioni della stessa applicazione (cfr: CSE-ATM; ISP-ATM; CSE-TCR; ISP-CSA).
La media di E risulta essere 0,78 (casi di test per hh-persona). Dalla figura 4.11 risulta che i valori di E siano poco dispersi, pertanto il valore della media può essere un buon indicatore per prevedere l’impegno persona necessario per la realizzazione di un piano di test con FIS. Per l’asserzione precedente ci si attende che tale media tenderà ad aumentare con il tempo perché si arricchirà il patrimonio di casi di test disponibile per ogni applicazione in essere.
TEST DI SISTEMA PER APPLICAZIONI WEB
Q4.7 - Qual è l’affidabilità di TEST COMPLETE?
L’uso di TEST COMPLETE deve consentire di gestire il patrimonio dei casi di test e dell’oracolo in modo che, in tutto il ciclo di vita di un’applicazione WEB, qualunque siano state le modifiche evolutive(aggiunta di nuove funzioni, cancellazione di vecchie funzioni, modifiche di funzioni esistenti), per ogni qualsivoglia istanza nel patrimonio dei casi di test questa risulti sempre un caso di test che sottoposto all’applicazione in esercizio generi sempre i risultati attesi, registrati nell’oracolo, in corrispondenza della stessa istanza.
Per verificare questa caratteristica su versioni diverse dello stesso software si rilevano le seguenti misure:
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato.
NET: insieme di casi di test estratti dal patrimonio comune, compresi nel piano di test.
Si calcola
TFP: tasso di falsi positivi = NFP/NT*100.
Sono stati eseguiti 2 casi di studio. I risultati sono riportati in figura 4.12. Lo stesso prodotto è stato testato con l’identico piano di test ma con diversi browser.
I falsi positivi riportati in tabella sono distinti rispetto alle due tipologie di browser che sono stati utilizzati durante i test sperimentali.
Figura 4.12. Dati di affidabilità rilevati dai test automatici
In seguito alle analisi di questi dati, l’ipotesi più plausibile è che con un maggiore addestramento del tool, questi falsi positivi si ridurranno sensibilmente, infatti le cause principali che li hanno prodotti sono le seguenti due:
- inserimento di asserzioni nel tool che non coprono il 100% dei possibili scenari; in questo caso, con raffinamenti successivi, è possibile perfezionare queste asserzioni;
- quando si utilizza l’OCR nativo del tool, esso deve essere tarato opportunamente in maniera tale da far funzionare le asserzioni.
Q4.8 - Qual è la stabilità di TEST COMPLETE?
L’uso di TEST COMPLETE deve consentire di gestire il patrimonio dei casi di test e dell’oracolo in modo che, ogni riesecuzione di qualsivoglia istanza del patrimonio dei casi di test, in tempi e condizioni diverse, produca sempre gli stessi risultati, registrati nell’oracolo ad applicazione WEB invariata.
Per verificare questa caratteristica sulle stesse versioni di software si esegue lo stesso piano di test più volte ma in condizioni diverse rilevando le seguenti misure per ogni versione e per ogni riesecuzione:
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato.
NET: insieme di casi di test estratti dal patrimonio comune, compresi nel piano di test.
AMB: descrizione dell’ambiente di prova
Si calcola
TFP: tasso di falsi positivi = NFP/NT*100.
Il prodotto sperimentale è la “Console V3 Phoenix” su cui sono state eseguite 10 prove dello stesso piano di test con due browser differenti: 5 con Google Chrome e 5 con Explorer.
I dati rilevati sono riportati in figura 4.13

Figura 4.13. Dati di stabilità rilevati dai test automatici con TEST COMPLETE
Dalla figura risulta che con Explorer si hanno risultati leggermente migliori di Google Chrome. La figura 4.14 mostra graficamente la dispersione di TFP differenziata per i due diversi browser confermando, come si può valutare anche dalla figura precedente, che questa è relativamente piccola. Il risultato di TFP, quindi, non è soddisfacente.
Anche questo risultato si ritiene sia dovuto alla ancora scarso addestramento del tool.
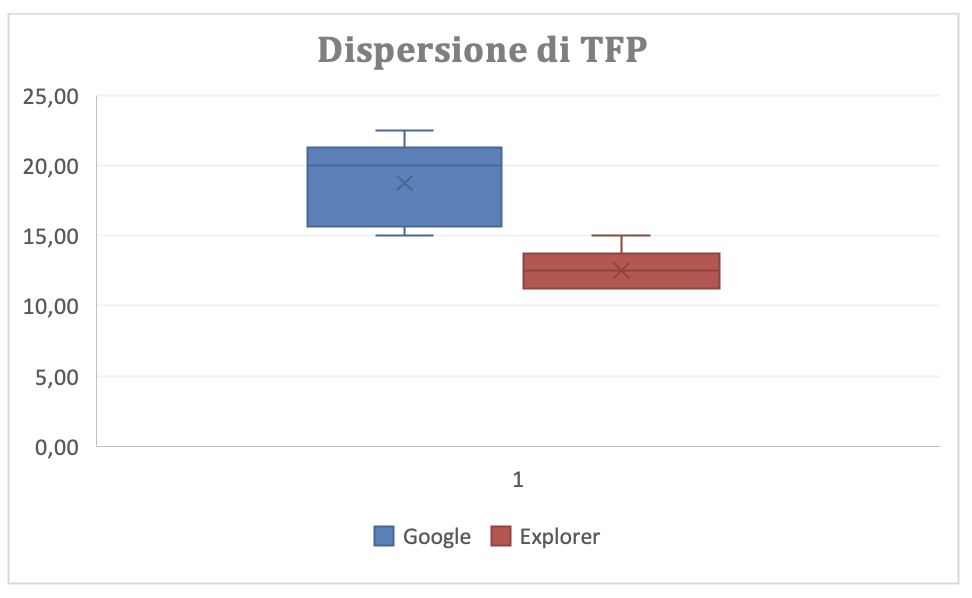
Figura 4.14. Dispersione di TFP con TEST COMPLETE
Q4.9 - Qual è la flessibilità di TEST COMPLETE?
L’uso di TEST COMPLETE, attraverso la strutturazione del patrimonio dei casi di test, deve consentire ai tester la selezione completa e corretta del set di casi di test utile a provare che dopo ogni modifica evolutiva (aggiunta di nuove funzioni, cancellazione di vecchie funzioni, modifiche di funzioni esistenti) tutte le funzioni impattate ma non cambiate nel comportamento dalla manutenzione dell’applicazione WEB si comportino come prima della modifica.
Per verificare questa caratteristica è stato impostato un caso di studio su quattro delivery successivi del prodotto sperimentale “Console V3 Phoenix”. Il piano di test di ogni delivery conteneva casi di test di regressione che sono stati estratti dal patrimonio che era stato popolato dai casi di test utilizzati per testare lo stesso prodotto fino alla delivery precedente.
Le misure rilevate sono:
CTA: numero di casi di test attesi nella selezione per il test di regressione sul prodotto testato.
CTS: numero di casi di test estratti nella selezione per il test di regressione per ogni prova sul prodotto.
CTD: numero di casi di test che differenziano i due insiemi precedenti= numero di casi di test attesi e non estratti+ numero di casi di test estratti ma non utili
Si calcola
TTD: tasso della differenza dei casi di test= CTD/CTA*100
I risultati sono riportati in Figura 4.15. Si inizia dall’incremento 2 perché l’incrementi 1 è il primo a popolare il patrimonio comune di test con il relativo oracolo.

Figura 4.15. Dati di flessibilità rilevati dai test automatici
Con il limitato campo sperimentale a disposizione, i valori di TTD sono incoraggianti per valutare la flessibilità del tool soddisfacente.
Q4.10 - Qual è la sistematicità di TEST COMPLETE?
L’uso di TEST COMPLETE consente ai tester di gestire il patrimonio dei casi di test ed in corrispondenza di gestire l’oracolo sistematicamente; ovvero, i contenuti delle due tecnologie risultano corrette indipendentemente dal tester che li ha prodotti e dal tempo in cui sono stati prodotti.
Per verificare questa caratteristica 2 tester diversi hanno prodotto gli stessi piani di test per 5 delivery del prodotto “Console V3 Phoenix”. Per ogni prova sono rilevate le seguenti misure:
NCT: numero di casi di test del piano eseguito per ogni prova sul prodotto testato.
NFP: numero di falsi positivi rilevati nel test di regressione per ogni prova sul prodotto testato.
DFP: numero di falsi positivi differenti rilevati dai due tester
Si calcola
TDFP: tasso delle differenze dei falsi positivi = DFP/NCT*100
In figura 4.16 sono mostrati i risultati:

Figura 4.16. Dati di sistematicità rilevati dai test automatici
Il tasso della differenza tra i falsi positivi è ragionevolmente piccolo. A rinforzo di questa affermazione è opportuno notare che: il numero complessivo degli NFP sono quasi uguali per i due soggetti sperimentali; la distribuzione degli errori è 3 volte a vantaggio del tester 1, 2 a vantaggio del tester 2. Perciò i due soggetti sperimentali hanno la stessa abilità ad utilizzare le tecniche di programmazione dell’esecuzione dei casi di test. Pertanto le tecniche di programmazione disponibili attualmente e la loro disseminazione sono soddisfacenti.
La media di TDFP (2,48) sperimentalmente accettabile ma potrebbe diminuire con un migliore addestramento del tool, come si è detto prima. In figura 4.17 è mostrata la box plot della dispersione di TDFP da dove si vede che questa è relativamente piccola quindi la media può essere considerata un buon indicatore della sistematicità.
In conclusione è trascurabile il rischio che il piano di test eseguito con TEST COMPLETE possa dare risultati diversi dipendentemente dal tester che lo ha programmato.
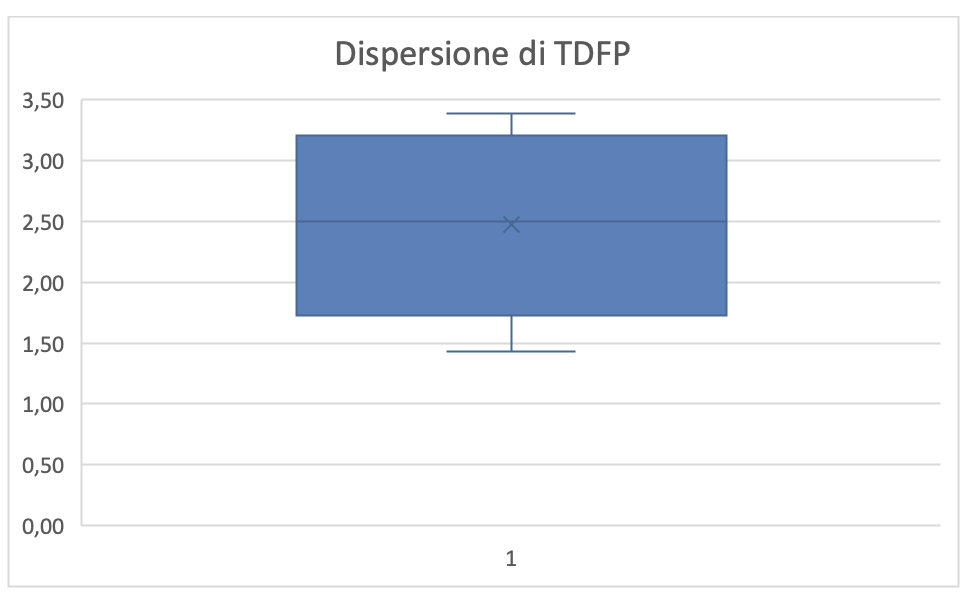
Figura 4.17. Distribuzione di TDFP per TEST COMPLETE
Q4.11 - Qual è la trasferibilità di TEST COMPLETE?
La conoscenza accumulata in TEST COMPLETE, i metodi e le tecniche definite per la programmazione dei casi di test devono essere facilmente trasferibili per costituire economicamente e tempestivamente competenze specializzate di tester per applicazioni web.
In questo caso si è potuto eseguire solo un corso che è stato necessario per introdurre nuove risorse nel team di sviluppo della “Console V3 Phoenix”. Le misure rilevate per validare l’onere del trasferimento tecnologico sono state le seguenti
TF: tempo in hh speso per la formazione dei Tester all’uso di TEST COMPLETE per la coorte Ima di tester.
TA: Tempo in hh speso per addestrare i Tester all’uso di TEST COMPLETE per la coorte Ima di tester.
{quesiti}: quesiti sollevati dai tester sia durante il corso sia durante le operazioni sperimentali, per la classe Ima di tester.
I dati rilevati sono riportati in Figura 4.18
Figura 4.18. Dati di trasferibilità per i TEST COMPLETE
Queste misure servono a prevedere il costo per la costituzione delle competenze specialistiche su TEST COMPLETE.
Di seguito i quesiti riscontrati:
- come si crea una variabile d’ambiente?
- come si parametrizza una variabile?
- come faccio a comparare due scritte che vedo a schermo nella pagina per creare un costrutto di tipo “if”?
- come importo un test in un altro progetto?
- se importo un test in un altro progetto come mai l’esecuzione non è uguale?
- come lancio tutto il pacchetto di test che ho registrato in un’unica volta?
- come aggiungo step in un test già esistente?
- come mai alcuni input che il programma dovrebbe riconoscere quando clicco a schermo, sono registrati sistematicamente in maniera erronea?
I quesiti indicano che per migliorare l’efficacia del corso è necessario migliorare i contenuti della parte e-learning per quanto riguarda la descrizione del tool.
Q4.12 - Qual è l’efficienza dei tester supportati da TEST COMPLETE?
Per valutare i costi che comporta la produzione di un piano di test con il TEST COMPLETE è opportuno indagare quale sia la efficienza dei tester supportati da questo tool.
L’indagine è stata condotta su sei delivery dello stesso prodotto sperimentale “Console V3 Phoenix”. I sei delivery sono in sequenza cronologica; quindi, ogni delivery utilizza il patrimonio di casi di test raccolti fino al precedente.
Le misure rilevate per ogni delivery sono:
ET: effort in hh-persona speso dal tester T per il piano di test sperimentale; in questo è compreso sia la selezione dei casi di test dal patrimonio comune sia la scrittura di nuovi test e la produzione del relativo oracolo
NCT New: numero di nuovi casi di test inseriti nel piano di test
NCT: numero di casi di test totali nello stesso piano di test
Si calcola
E: efficienza = NCT/ET casi di test per hh
L’effort è misurato dall’ora di inizio schedulata per l’assegnazione della prova ad un tester fino all’ora di fine della prova, senza considerare il tempo speso dallo strumento per eseguire automaticamente il test di regressione. Il momento della fine della prova è quello in cui il tester consegna su TFS il risultato previsto dalla prova. Il tempo speso da TEST COMPLETE si rileva dallo stesso strumento, questo deve essere sottratto al tempo che intercorre dall’inizio alla fine della prova, come risulta da TFS per poter ricavare esattamente l’effort speso dal tester.
I dati rilevati sono riportati nella Figura 4.19.

Figura 4.17. Dati inerenti l’efficienza per TEST COMPLETE
Dalla figura 4.17 si evince che il patrimonio di casi di test che si accumula in TEST COMPLETE assicura che la efficienza nella produzione del piano di test aumenta incrementalmente con le successive evoluzioni della stessa applicazione.
Dalla figura 4.18 risulta che i valori di E sono molto dispersi a causa del riuso dei casi di test accumulati nel patrimonio. Per l’asserzione precedente ci si attende che E tenderà ad aumentare con il tempo perché si arricchirà il patrimonio di casi di test nel tempo.
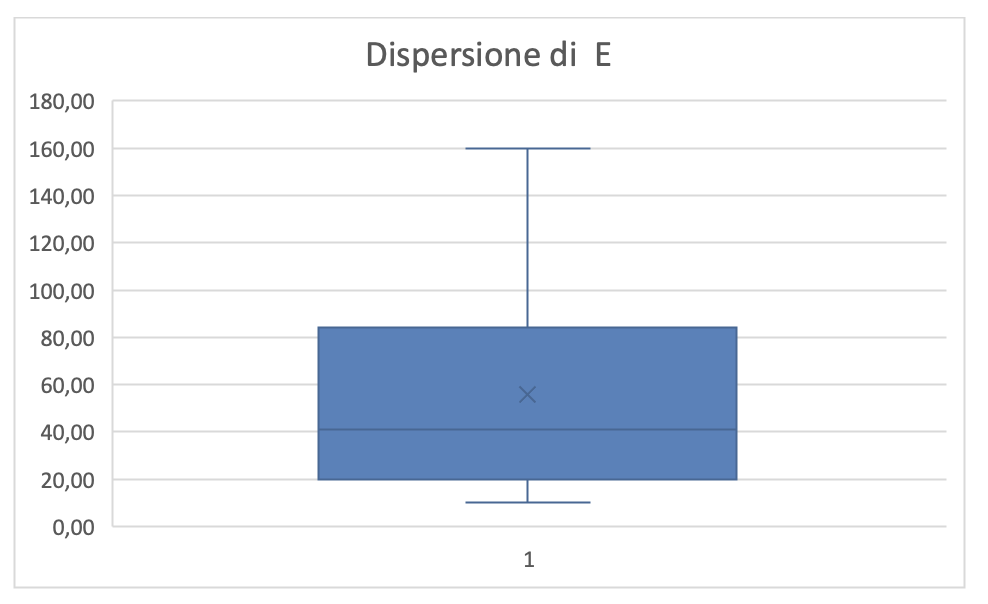
Figura 4.18 Dispersione di E per TEST COMPLETE